Hoofdstuk 3 Studiedesign
Alle kennisclips die in dit hoofdstuk zijn verwerkt kan je in deze youtube playlist vinden: Kennisclips Hoofdstuk3
Link naar webpage/script die wordt gebruik in de kennisclips: script Hoofdstuk3
3.1 Inleiding
Centraal in wetenschappelijk onderzoek is de wens en noodzaak om theorie-gebaseerde kennis empirisch (d.w.z. door middel van observatie) te verifiëren en op te bouwen. Terwijl theorie-gebaseerde kennis voortvloeit uit hypothesen omtrent het bestudeerde biologische of chemische proces, ontstaat empirische kennis door lukraak subjecten (mensen, planten, dieren) uit een doelpopulatie te trekken volgens een gestructureerd schema en hen vervolgens te observeren. Dit gestructureerde schema, dat ondermeer vastlegt welke en hoeveel subjecten in de studie worden opgenomen en eventueel wie welke experimentele interventie zal ondergaan, noemt men het design van de studie of de proefopzet. Met een goed design kunnen betrouwbare conclusies worden getrokken op basis van de gegevens. Het bepaalt immers welke informatie wel en niet in de dataset vervat zal zijn. Fouten bij het design van een studie kunnen soms gecorrigeerd worden door de statistische analyse, maar zijn helaas vaak onherroepelijk. Het design is daarom van cruciaal belang voor een studie en vereist evenveel aandacht als de uiteindelijke statistische analyse van de observaties. Ook in deze cursus vormen de concepten in dit hoofdstuk rond design wellicht het meest belangrijke onderwerp, hoewel we er slechts beknopt op in kunnen gaan. De ideeën lijken eenvoudig, maar dat is vaak een bedrieglijke indruk!
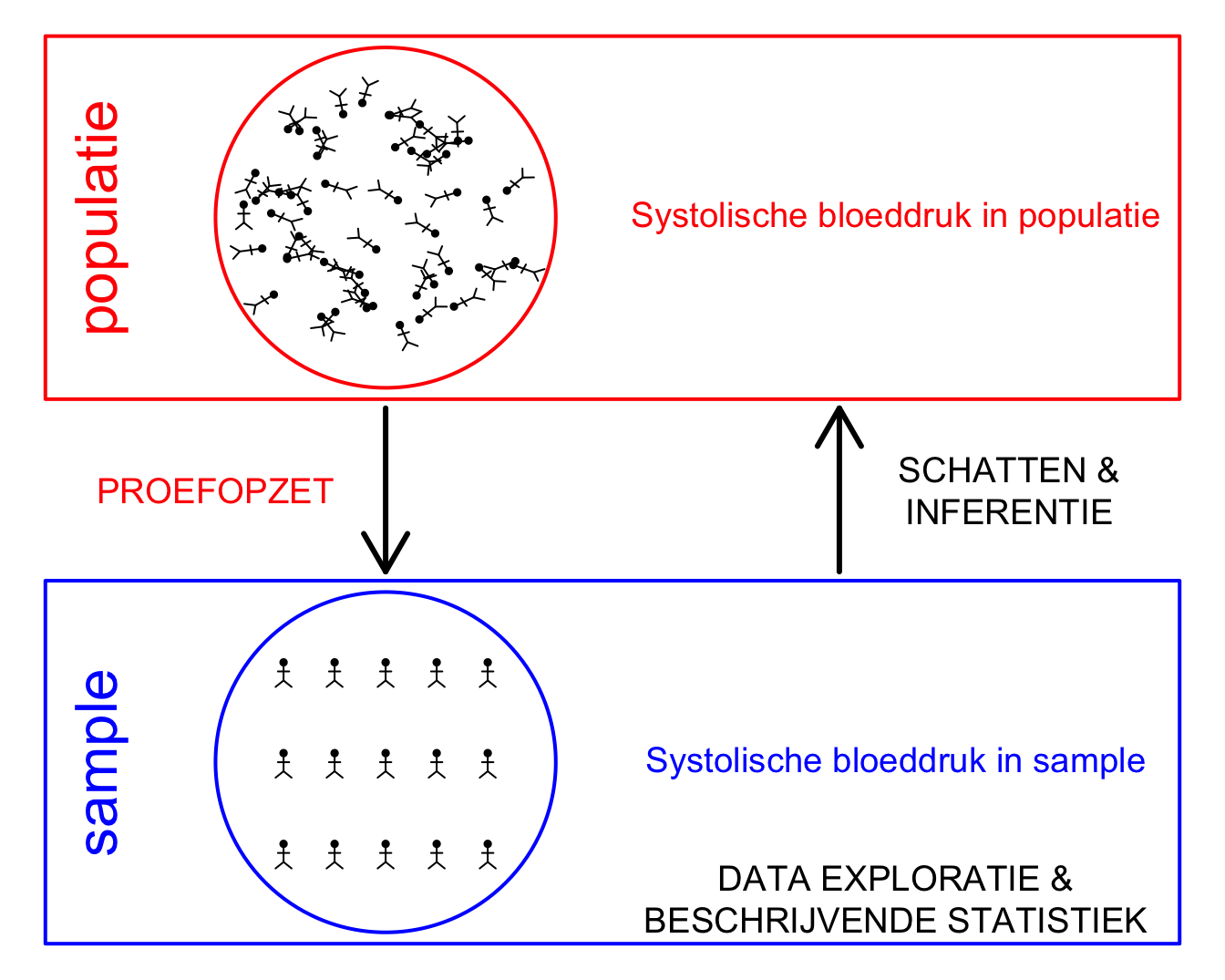
Figuur 3.1: Verschillende stappen in een studie. In dit hoofdstuk ligt de focus op proefopzet.
3.2 Steekproefdesigns
In de praktijk vestigt men de interesse van een onderzoek op een bepaalde biologische populatie. Vervolgens zal men een geschikt type en grootte van monsters of stalen (of meer algemeen experimentele eenheden en/of subjecten genoemd doorheen deze cursus) definiëren waarvoor men metingen zal verzamelen. Bijvoorbeeld, indien men de grootte van de populatie salamanders van de species Plethodon jordani wenst te bestuderen, kan men de aandacht van het onderzoek vestigen op de bestaande populatie P. jordani in de Great Smoky Mountains (d.i. de populatie) en vervolgens het aantal salamanders tellen op oppervlakte-eenheden van 10 m\(^2\) (die eenheden zijn de stalen of “experimentele eenheden”; voor elke experimentele eenheid bekomt men aldus een meting). Indien men de impact van roofvissen op zeebodemhabitats wenst te evalueren, dan kan het onderzoek de aandacht vestigen op de zeebodem binnen een afstand van 500 m voor de Belgische Noordzeekust (d.i. de biologische populatie) en kunnen vervolgens metingen worden verzameld op stukjes zeebodem met een straal van 1 m (d.i. de “stalen” in de studie). Omdat het in de praktijk bijna nooit mogelijk is om de hele populatie te onderzoeken (alle salamanders in de Great Smoky Mountains, de ganse zeebodem binnen een afstand van 500 m voor de Belgische Noordzeekust), zal men zich beperken tot gegevens voor een zogenaamde steekproef, een beperkte verzameling stalen, experimentele eenheden of subjecten uit de populatie.
Welke subjecten uit de populatie men precies zal bestuderen, zal uiteraard zijn weerslag hebben op de resultaten van de uiteindelijke analyse van de gegevens. Opdat de resultaten die men observeert voor de steekproef veralgemeenbaar zouden zijn naar de ganse studiepopulatie, is het noodzakelijk dat men de subjecten uit de steekproef zodanig kiest dat ze representatief zijn voor de populatie. De basismethode om dat te realiseren, heet eenvoudige lukrake steekproeftrekking (in het Engels: simple random sampling). Ze bestaat erin te garanderen dat elk subject in de populatie een zelfde kans heeft om in de steekproef terecht te komen. Zo kan men bijvoorbeeld elke muis in een kooi een nummer geven en vervolgens lukraak een aantal \(n\) van die nummers trekken. In de praktijk, en in het bijzonder in de veldbiologie, is die methode echter vaak moeilijk toe te passen omdat de subjecten in de populatie bijvoorbeeld geen goed onderscheiden habitats vormen, niet op voorhand genummerd kunnen worden of omdat de populatie een te groot gebied bestrijkt. Zo is het bijvoorbeeld niet makkelijk om een eenvoudige lukrake steekproef van salamanders in de Great Smoky Mountains te bekomen omdat het bestudeerde gebied zeer groot is en de salamanders uiteraard niet genummerd kunnen worden. In die gevallen gaan biologen vaak over op haphazard sampling, waarbij men op een minder formele manier stalen verzamelt, maar er toch voor probeert te zorgen dat de resultaten niet vertekend worden doordat bepaalde subjecten meer kans hebben om in de steekproef terecht te komen. Bijvoorbeeld kan men een computer lukraak plaatsen laten aanduiden in de Great Smoky Mountains en kan men vervolgens metingen proberen te verzamelen voor de eerste salamander die telkens in de buurt van de aangeduide plaatsen voorbijkomt.
Sommige steekproefdesigns houden expliciet rekening met heterogeniteit in de populatie waaruit een steekproef wordt genomen. Bij gestratificeerde lukrake steekproeven (in het Engels: stratified random samples) wordt de populatie opgedeeld in verschillende strata, die goed onderscheiden subgroepen in de populatie identificeren, en worden vervolgens eenvoudige lukrake steekproeven uit elk stratum genomen. Stel bijvoorbeeld dat men karakteristieken van stenen in een rivier wenst te beschrijven en dat stenen in verschillende habitats voorkomen (rotsige, ondiepe waters, diepe waters, stille binnenwaters,…), dan kan het zinvol zijn om een gestratificeerde lukrake steekproef te nemen om ervoor te zorgen dat er binnen elk stratum (d.i. elke habitat) een voldoende aantal stenen verzameld worden.
Bij geclusterde steekproeftrekking (in het Engels: cluster sampling) worden clusters van meer verwante subjecten uit de populatie getrokken. Stel bijvoorbeeld dat we de impact van verschillende vormen van beschadiging aan bladeren van een boom wensen te meten, dan kunnen we in een eerste fase een eenvoudige lukrake steekproef van bomen bepalen. Vervolgens kunnen we in een tweede fase binnen elke boom een eenvoudige lukrake steekproef van bladeren bepalen en de verschillende gekozen bladeren aan verschillende vormen van beschadiging onderwerpen. Dit noemt men (two stage) cluster sampling omdat bladeren afkomstig van een zelfde boom meer verwant en bijgevolg geclusterd zijn. We zullen later zien dat men in de analyse van gegevens uit dergelijke studie met die clustering rekening moet houden.
Tenslotte steunt men in de biologische wetenschappen ook vaak op systematische steekproeven waarbij men bijvoorbeeld monsters neemt die op vaste afstand van elkaar bekomen worden of op voorafgekozen tijdstippen, en om die reden niet volledig lukraak genoemd kunnen worden. Dit wordt vaak gebruikt wanneer men een omgevings- of tijdsgradiënt wenst te beschrijven voor een bepaald proces, zoals de wijziging in rijkdom aan species naarmate men zich verwijdert van een vervuilingsbron. Dergelijke designs zijn nuttig en logistiek zeer praktisch, maar kunnen vertekende resultaten opleveren wanneer de monsters op specifieke plaatsen genomen worden die samenvallen met een ongekende omgevings- of tijdsgradiënt (d.i. indien de gekozen plaatsen selectief zijn en afwijkend van de globale omgevings- of tijdsgradiënt).
3.2.1 Replicatie
Replicatie betekent dat herhaaldelijke observaties worden bekomen, op verschillende plaatsen, voor verschillende dieren of planten, op verschillende tijdstippen, … Dergelijke herhalingen zijn essentieel in empirisch onderzoek omdat biologische en ecologische systemen vaak zeer variabel zijn en de beschikbaarheid van meerdere observaties toelaat om ruis op de gegevens te drukken. Hoewel biologen, biotechnologen en biochemici zich goed bewust zijn van de nood voor replicatie wordt vaak misbegrepen op welke schaal die herhalingen moeten bekomen worden. Wellicht is er geen enkel aspect van studiedesign dat meer verwarring veroorzaakt bij wetenschappers dan dit. Stel bijvoorbeeld dat men een studie wenst op te zetten om het effect van bosbranden op de rijkdom aan ongewervelde dieren te onderzoeken. Meestal zal men dan gebruik maken van natuurlijke bosbranden. Stel dat 1 verbrand gebied gelocaliseerd wordt en vergeleken wordt met een naburig gebied waar geen bosbrand plaatsvond. Stel verder dat men binnen elk gebied verschillende stalen bodemkorst neemt om de rijkdom aan ongewervelden te bepalen. Dan beschikt men wel over herhaaldelijke metingen (namelijk verschillende stukken bodemkorst per gebied), maar niet op de juiste schaal. De metingen voor de rijkdom aan species die men uit het verbrande gebied bekomen heeft, meten immers de impact van dezelfde brand. Als gevolg daarvan kan men op basis van eventuele verschillen in species rijkdom tussen beide gebieden niet bepalen of ze het gevolg zijn van de brand dan wel van andere verschillen tussen beide gebieden die eveneens een impact op ongewervelden hebben. Uit dergelijke vergelijking kan men hoogstens besluiten dat de gebieden al dan niet verschillen, maar niet waardoor ze verschillen.
De herhaalde stukken bodemkorst in bovenstaand voorbeeld stellen substeekproeven voor. Deze stellen geen herhalingen voor van de bestudeerde interventie (bosbranden) en worden daarom pseudoreplicaties genoemd. Pseudoreplicaties zijn nuttig omdat ze replicaties zijn (op een zeker niveau) en daardoor toelaten om een deel van de ruis op de gegevens weg te middelen. In sommige studies zijn echte replicaties onmogelijk en is het bijgevolg onvermijdelijk om zijn toevlucht tot pseudoreplicaties te nemen. Bijvoorbeeld, indien men een experiment uitvoert dat kamers van constante temperatuur vereist, dan kan het best zijn dat er binnen een gegeven instituut slechts een tweetal dergelijke kamers beschikbaar zijn omwille van hun hoge kost. Indien men bijvoorbeeld de impact wenst te onderzoeken van rioollozing op de biomassa van phytoplankton in een bepaalde kuststreek, dan is er vaak maar 1 riool waarin men echt geïnteresseerd is, terwijl het aantal naburige lokaties zonder riool zeer uitgebreid kan zijn. In dat geval zal men vaak stalen nemen op meerdere plaatsen zonder riool om in ieder geval de variatie tussen controlesites (d.i. sites zonder rioollozing) te minimaliseren. Before-After-Control-Impact (BACI) designs proberen verder informatie te winnen door zowel metingen te nemen vóór de interventie (bvb. het plaatsen van een riool) als na de interventie.
3.3 Experimentele studies
Studiedesigns worden opgesplits in experimentele studies of experimenten waar de onderzoeker eerst het biologische systeem manipuleert en vervolgens observeert, en observationele studies waar de onderzoeker enkel observeert zonder zelf in het systeem in te grijpen. In deze sectie gaan we dieper in op het eerste type studies. Observationele studies worden besproken in Sectie 3.4.
Een experiment is een reeks observaties die gemaakt worden onder condities die gecontroleerd worden door de onderzoeker. De onderzoeker controleert hierbij verschillende factoren (zoals de keuze van de interventie voor een locatie, plant, dier), met als doel een zuiver antwoord op de gestelde onderzoeksvraag te bepalen.8
Einde definitie
Bijvoorbeeld, wanneer een dierenfysioloog 2 behandelingen wenst te vergelijken tussen experimentele dieren, dan kan hij - zoals we in dit hoofdstuk zullen zien - vermijden dat het behandelingseffect vertekend9 is door vergelijkbare groepen dieren te creëren; bijvoorbeeld, door lukraak (bijvoorbeeld door het opgooien van een muntstuk) te bepalen welke behandeling aan welk dier wordt toegediend.
3.3.1 De Salk Vaccin Veldstudie
Om de basisprincipes van experimentele designs in te voeren, gebruiken we als rode draad de Salk Vaccin Veldstudie. Vooraleer dieper op deze studie in te gaan, schetsen we de historische context.
De eerste polio-epidemie in de Verenigde Staten brak uit in 1916 en kostte aan honderdduizenden mensen, vooral kinderen, het leven. Tegen de jaren 1950 waren er verschillende vaccins ontwikkeld. Vooral het vaccin dat door John Salk werd ontwikkeld, leek veelbelovend omdat het zich veilig en effectief had getoond in laboratoriumstudies. In 1954 werd door de National Foundation for Infantile Paralysis (NFIP) een grote studie opgezet om de effectiviteit van het vaccin buiten het laboratorium na te gaan. Meer concreet wenstte men na te gaan wat de invloed was van vaccinatie op de polio-incidentie.
De incidentie van een bepaalde ziekte of aandoening (bvb. polio) wordt gedefinieerd als het verwachte aantal nieuwe gevallen van die ziekte dat optreedt gedurende een vooraf bepaald tijdsinterval, uitgedrukt per eenheid van een ziektevrije populatie. Het drukt m.a.w. de kans uit dat een individu zonder de bestudeerde aandoening tijdens het gegeven tijdsinterval deze aandoening zal opdoen.
De prevalentie van een bepaalde ziekte wordt gedefinieerd als de proportie individuen met de ziekte in een bepaalde populatie op een bepaald punt in de tijd.
Einde definitie
Stel dat de NFIP het vaccin gewoon had toegediend aan een groot aantal kinderen en dat ze een daling observeerden in de incidentie van polio van 1953 naar 1954. Dit betekent dat de kans dat een lukraak polio-vrij kind een polio-infectie opdeed in de loop van 1954 (d.i. de incidentie van polio in 1954), lager is dan de kans dat lukraak polio-vrij kind een polio-infectie opdoet in de loop van 1953 (d.i. de incidentie van polio in 1953). In dat geval kan men niet zomaar besluiten dat het vaccin effectief is. Immers, afgezien van de introductie van een vaccin, varieert de incidentie van polio van jaar tot jaar. Zo zou men, indien het vaccin niet effectief was, toch een daling in polio-incidentie van 1953 naar 1954 kunnen vaststellen in geval 1954 geen epidemisch jaar zou zijn.
De enige manier om te ontdekken of het vaccin effectief is, is om gelijktijdig de incidentie van polio in 1954 te vergelijken tussen een groep gevaccineerde kinderen (doorgaans cases genoemd) en een groep niet-gevaccineerde kinderen (doorgaans controles genoemd). Dit is wat de NFIP heeft gedaan. De deelnemers aan de studie waren kinderen uit de leeftijdsgroepen die het meest vatbaar waren voor polio. De studie verliep in verschillende schooldistricten in de Verenigde Staten waar het risico op polio hoog was. Aan ongeveer 350000 kinderen uit de tweede graad werd vaccinatie voorgeschreven. Voor 125000 van hen weigerden de ouders toestemming te geven om deze vaccinatie te laten doorgaan, zodat de groep cases uiteindelijk uit de overige 225000 kinderen bestond. Ongeveer 750000 kinderen uit de eerste en derde graad werden vrijwillig niet gevaccineerd; zij vormden de controles.
Het feit dat de groep cases en de groep controles een verschillende grootte hebben is niet problematisch zolang men niet het absolute aantal, maar het percentage polio-besmettingen tussen beide groepen vergelijkt. Toch hoeft een geobserveerd verschil in incidentie tussen gevaccineerde en niet-gevaccineerde kinderen nog steeds niet noodzakelijk te impliceren dat het vaccin effectief is. Hier zijn verschillende redenen voor:
- Ten eerste zou het kunnen dat men door toeval een verschil in incidentie waarneemt tussen beide groepen, doordat er per toeval bijvoorbeeld relatief gezien minder kinderen in de gevaccineerde groep polio ontwikkelen. In Hoofdstuk 5 zullen we methoden aanleren om uit te maken of een geobserveerd vaccinatie-effect (d.w.z. een vaccinatie-effect dat geschat of berekend werd o.b.v. de gegevens) al dan niet toevallig is.
- Ten tweede zou het kunnen dat kinderen uit de tweede graad sowieso meer vatbaar zijn voor polio en er, afgezien van het werkelijke vaccin-effect, voor de cases dus een hogere incidentie wordt verwacht.
- Ten derde is het zo dat vooral ouders uit hoge-inkomens gezinnen geneigd waren om de toestemming te geven hun kind te laten vaccineren, zodat de groep cases hoofdzakelijk bestaat uit kinderen van hoge-inkomens gezinnen. Deze kinderen zijn meer vatbaar voor polio omdat ze, wegens de betere hygiënische omstandigheden in deze gezinnen, minder antilichamen tegen polio ontwikkeld hebben.
Het geobserveerde verschil in incidentie tussen gevaccineerde en niet-gevaccineerde kinderen weerspiegelt daarom niet alleen de effectiviteit van het vaccin, maar ook het feit dat kinderen uit graad 2 mogelijks niet vergelijkbaar zijn met de resterende kinderen en het feit dat cases, omwille van betere hygiënische omstandigheden, meer vatbaar zijn voor polio dan controles. In het bijzonder is het om die reden mogelijk om, zelfs als het vaccin effectief is, een gelijke incidentie voor cases en controles vast te stellen. In dat geval verwart men het effect van het vaccin met het feit dat cases meer vatbaar zijn voor polio dan controles.
De statistische les die we hier algemeen uit kunnen trekken, is dat de verschillende interventiegroepen zo vergelijkbaar mogelijk moeten zijn bij de bepaling van het effect van een interventie, opdat elk verschil in respons tussen de groepen volledig kan toegeschreven worden aan de verschillende interventie. Wanneer de groepen cases en controles niet volledig vergelijkbaar zijn in een bepaalde factor (zoals de vatbaarheid voor polio, maar niet de interventie zelf), dan is het mogelijk dat het effect van die factor verward (in het Engels: confounded) wordt met het effect van de interventie. Men noemt die factor dan een confounder voor het effect van de interventie. De belangrijkste beperking op de ondubbelzinnige interpretatie van studieresultaten is het probleem van confounding.
Hairston (1980) bestudeerde de stelling dat 2 soorten salamander (P. jordani en P. glutinosus) in de Great Smoky Mountains mekaar rivaliseren. Hij zette daartoe experimenten op waarbij P. glutinosus verwijderd werd van bepaalde territoria. De populatie van P. jordani begon toe te nemen in de 3 jaren die volgden op de verwijdering van de salamanders, maar nam al even sterk toe op controleterritoria waar P. glutinosus niet verwijderd was. Had Hairston geen controleterritoria onderzocht, dan had hij mogelijks de toename in de populatie van P. jordani verkeerdelijk toegeschreven aan het verwijderen van P. glutinosus.
Einde voorbeeld
Confounding is het probleem dat verschillen ten gevolge van verschillende experimentele interventies niet kunnen losgekoppeld worden van andere factoren, confounders genoemd, die verschillen tussen de interventiegroepen. Een confounder manifesteert zich als een variabele die geassocieerd is met de blootstelling of interventie (bvb. gevaccineerd of niet) en de uitkomst (bvb. polio-geïnfecteerd of niet), maar die door geen van beiden zelf beïnvloed wordt. Bijvoorbeeld, vatbaarheid voor polio is geassocieerd met de keuze van de ouders om hun kind te laten vaccineren (d.i. de blootstelling) alsook met de infectiestatus van het kind (d.i. de uitkomst), maar wordt door geen van beiden zelf veroorzaakt. Confounders verstoren de associatie tussen blootstelling en uitkomst zodat de geobserveerde associatie tussen beiden mogelijks niet het pure effect (d.i. het causale effect) van die blootstelling op die uitkomst uitdrukt.
Einde definitie
Om het effect te onderzoeken van roofvissen op mariene zeebodemhabitats zou men gebieden met en zonder viskooien kunnen vergelijken. Als men vervolgens verschillen observeert tussen beide types gebieden, dan kan dat het gevolg zijn van het verwijderen van roofvissen (via de kooien), maar eveneens van de aanwezigheid van kooien (bijvoorbeeld, door schaduw die de kooi afwerpt, door de afgenomen waterstroming, …). Het effect van roofvissen verwijderen wordt dus mogelijks verward met het effect van kooien plaatsen. De aanwezigheid van kooien manifesteert zich hier dus als een confounder. Om dergelijke confounding te vermijden, kan men controlekooien met grote gaten plaatsen waar de vis vrij in en uit kan zwemmen, maar die voor de rest vergelijkbaar zijn met de experimentele kooien. In dat geval zijn beide studiegebieden van kooien voorzien en zal een vergelijking van experimentele en controlekooien duidelijk een veel meer betrouwbare evaluatie toelaten van het effect van roofvissen. Toch blijft dergelijke vergelijking niet gegarandeerd vrij van confounding. Bijvoorbeeld, als het effect van kooien plaatsen er voornamelijk in bestaat om de stroming van water (en bijgevolg sedimentatie) te beïnvloeden, dan speelt de vraag of de stroming van water ook niet beïnvloed wordt door het feit dat vissen, omwille van de grote gaten, makkelijker in controlekooien zwemmen dan in experimentele kooien.
Einde voorbeeld
Heel wat experten in volksgezondheid zagen de problemen met het NFIP design en suggereerden dat de controles uit dezelfde populatie moesten gekozen worden als de cases (d.w.z. dat ze moesten vergelijkbaar zijn). Vergelijkbaarheid van beide groepen garanderen, zou kunnen gebeuren op basis van menselijk oordeel. Ervaring heeft niettemin aangetoond dat dit vaak niet succesvol is omdat het zich makkelijk leent tot het bewust of onbewust bevoordelen van de ene groep versus de andere. Het is daarom aangewezen om randomisatieprocedures toe te passen, waarbij de toewijzing van mensen aan verschillende interventie-armen volledig lukraak gebeurt. Men zegt in dat geval dat de studie gerandomiseerd gecontroleerd(in het Engels: randomized controlled) is.
Een gerandomiseerd gecontroleerde studie is een experiment waarbij de toewijzing van subjecten aan de verschillende interventie-armen volledig lukraak gebeurt zodat de toewijzing van een gegeven subject onmogelijk op voorhand voorspeld kan worden. Als gevolg hiervan zijn de verschillende interventiegroepen (in principe10) in alle gekende en ongekende factoren (zoals leeftijd, lichaamsgewicht, vatbaarheid voor polio …) vergelijkbaar zodat geobserveerde verschillen in uitkomst tussen de verschillende groepen (in principe) kunnen toegeschreven worden aan de interventie (d.i. het vaccin).
Einde definitie
Naast de NFIP studie werd voor het Salk vaccin een gerandomiseerd gecontroleerde studie opgezet waarbij de beslissing om aan een gegeven kind al dan niet het vaccin toe te dienen, gemaakt werd door het opgooien van een muntstuk. De randomisatie werd uitgevoerd onder kinderen die van hun ouders de toestemming kregen om zich te laten vaccineren, indien ze aan de vaccin-groep zouden toegewezen worden. Door de randomisatie pas uit te voeren na het krijgen van de toestemming tot vaccinatie, kon men vermijden dat er differentiële uitval was van kinderen in beide groepen. Met differentiële uitval wordt bedoeld dat de reden om niet deel te nemen aan de studie verschillend is voor de test-en controlegroep. Dit kan vooral voorkomen in klinische studies (d.i. experimenten bij mensen) wanneer 1 van beide behandelingen (in de test- of controle-arm) een zware heelkundige ingreep is die vooral door ernstig zieke mensen gemeden wordt. Wanneer er na randomisatie differentiële uitval optreedt, dan kan men niet langer vergelijkbare groepen garanderen.
In de gerandomiseerde Salk vaccin studie werd aan kinderen in de controle-groep een placebo toegediend. Dat is een inerte, inactieve behandeling; in dit geval een injectie van zout opgelost in water. Tijdens de studie waren de kinderen blind voor de behandelingscode (d.i. ze wisten niet aan welke interventiegroep ze toegewezen waren). Dit heeft tot gevolg dat hun respons op de vaccinatie (d.i. of ze al dan niet polio ontwikkelen) het gevolg was van het al dan niet krijgen van het vaccin, en niet van het `idee’ om al dan niet behandeld te zijn. In deze studie lijkt het misschien onwaarschijnlijk dat het idee om gevaccineerd te zijn de kinderen zou kunnen beschermen tegen polio, maar de rol van het onderbewustzijn is soms sterker dan vermoed wordt. Zo heeft men in een studie van patiënten met ernstige post-operatieve pijn vastgesteld dat de pijn bij een derde van de patiënten spontaan verdween na inname van een volledig neutrale substantie!
Het blinderen van de toegediende interventie laat algemeen toe om een zo objectief mogelijk beeld van het interventie-effect te verkrijgen. Analoog gebruiken fysiologen in dierenexperimenten injectie met een zoutoplossing als controle i.p.v. geen injectie. Op die manier vermijden ze dat verschillen die men observeert tussen controledieren en dieren die een toxische substantie ingespoten krijgen, niet het gevolg zijn van de injectieprocedure (bijvoorbeeld, van wondjes ten gevolge van de inspuiting), maar van de ingespoten substantie zelf.
Een verdere voorzorgsmaatregel in de Salk vaccin studie was dat ook de dokters, die moesten vaststellen of de kinderen geïnfecteerd waren, blind waren voor de behandeling. Op die manier voorkwam men dat de arts bewust of onbewust kennis omtrent de gekregen vaccinatie zou gebruiken om een beslissing te nemen over de infectiestatus. Dit zou kunnen voorvallen wanneer het resultaat van de polio-test dubieus was en de arts (bewust of onbewust) kennis omtrent de vaccinatie-status van zijn patiënt gebruikt om de infectie-status te bepalen. Om dezelfde reden zijn ook dierenfysiologen idealiter blind voor de substantie die bij elke rat ingespoten werd.
Omdat noch de arts, noch de patiënt in de Salk vaccin studie wisten welke behandeling werd toegediend, wordt deze studie dubbel blind genoemd. Dubbel blinde studies vereisen dat de verschillende interventies er hetzelfde uitzien.
| Aantal | Incidentie | |
|---|---|---|
| Vaccin | 225000 | 25 |
| Controle | 725000 | 54 |
| Geen toestemming | 125000 | 44 |
Tabellen 3.1 en 3.2 geven de resultaten weer die geobserveerd werden in de NFIP studie en het dubbel blinde gerandomiseerd gecontroleerde (in het Engels: double blind randomized controlled) experiment. Op basis van Tabel 3.2 stellen we vast dat de incidentie daalt van 71 tot 28 gevallen per 100000 per jaar als gevolg van toediening van het vaccin. De enige vraag die resteert is of dergelijk verschil in incidentie gewoon door toeval kan ontstaan wanneer in werkelijkheid het vaccin geen effect zou hebben. Een gevorderde statistische analyse heeft aangetoond dat het bijna onmogelijk is om dergelijk verschil in incidentie te observeren door toeval, wanneer het vaccin geen effect heeft. We mogen dus besluiten dat het Salk vaccin effectief is.
Merk tenslotte op dat er inderdaad confounding optreedt in de NFIP studie. Immers de polio-incidentie lijkt er veel minder te dalen dan in de gerandomiseerde studie, namelijk van 54 naar 25 per 100000 per jaar als gevolg van het vaccin (zie Tabel 3.1). De oorzaak is dat de controlegroep in deze studie kinderen bevat die minder vatbaar zijn voor polio dan de vaccin-groep.
| Aantal | Incidentie | |
|---|---|---|
| Vaccin | 200000 | 28 |
| Controle | 200000 | 71 |
| Geen toestemming | 350000 | 46 |
3.3.2 Gerandomiseerde gecontroleerde studies
Bij randomisatie heeft elk subject in de studie (bijvoorbeeld, elk kind in de Salk vaccin studie, elke studieplaats op de zeebodem waar men een kooi wil plaatsen) een gekende kans om elke interventie te krijgen (bvb. bij het opgooien van een muntje heeft men 50% kans om het vaccin te krijgen en 50% kans om het placebo te krijgen), maar de te ontvangen behandeling kan niet voorspeld worden. Vreemd genoeg wordt de nood aan randomisatie niet steeds ingezien en maakt men vaak verkeerdelijk geen onderscheid met systematische allocatie.
Systematische allocatie of louter toevallige allocatie (in het Engels: haphazard allocation) is een toewijzingsmethode die mogelijks op een lukraak mechanisme lijkt, maar waarbij men de toewijzing van (sommige) subjecten op voorhand kan voorspellen.
Einde definitie
Een typisch voorbeeld van een systematische toewijzingsmethode is er één waarbij subjecten afgewisseld toegewezen worden aan de controle- of interventiegroep. Het feit dat men hier de toewijzing van elk subject op voorhand kan voorspellen, kan tot gevolg hebben dat de onderzoeker de toewijzing manipuleert. In medisch onderzoek is het in het verleden zo meermaals gebeurd dat artsen de al te zieke patiënten die in principe aan de controle arm zouden moeten toegewezen worden, later op bezoek laten komen (zodat ze de testbehandeling krijgen) of niet in de studie opnemen. Dit kan er op zijn beurt voor zorgen dat de verschillende groepen niet langer vergelijkbaar zijn. Om systematische allocatie te vermijden, is het van belang om een degelijke randomisatietechniek toe te passen. In de volgende paragrafen geven we een aantal mogelijkheden hiertoe.
Bij eenvoudige randomisatie worden subjecten lukraak toegewezen aan interventie A of B door het opgooien van een muntje, dobbelsteen, … Vaak is het efficiënter om via de computer een randomisatielijst te genereren die het proces van het opgooien van een muntje nabootst. Dit vermijdt tevens de mogelijkheid dat de onderzoeker niet naar behoren zou randomiseren (door bvb. het muntje zolang op te gooien tot de gewenste interventiecode te zien is).
Hoewel eenvoudige randomisatie aan iedereen evenveel kans geeft om behandeling A of B te krijgen, verzekert het niet dat beide groepen uiteindelijk even groot zullen zijn. Zelfs in relatief grote studies kan door toeval het verschil in aantal deelnemers in elke groep relatief groot zijn. Men kan aantonen dat, als gevolg hiervan, het interventie-effect doorgaans minder nauwkeurig of minder precies geschat kan worden op basis van de gegevens dan wanneer beide groepen even groot zouden zijn. Daarmee wordt bedoeld dat wanneer men de studie meermaals zou uitvoeren onder identieke omstandigheden, de resultaten doorgaans meer variabel zullen zijn van studie tot studie wanneer de relatieve grootte van beide groepen onbeperkt is, dan wanneer men telkens groepen van gelijke grootte eist.
Om na randomisatie 2 behandelingsarmen van gelijke grootte te bekomen, kan gebalanceerde of beperkte randomisatie (in het Engels: balanced of restricted randomisation) worden gebruikt. Hierbij wordt de randomisatieprocedure zó georganiseerd dat gelijke aantallen subjecten worden toegewezen aan interventie A of B per blok van bijvoorbeeld 4 subjecten. Eén methode om dat te doen is om enkel sequenties te beschouwen van de vorm (1) AABB, (2) ABAB, (3) ABBA, (4) BABA, (5) BAAB, (6) BBAA. Met behulp van een dobbelsteen of randomisatielijst wordt lukraak een nummer van 1 tot 6 gekozen. Stel dat het 1 is. Dan worden de 2 eerstvolgende subjecten toegewezen aan A en de 2 daarna aan B. Vervolgens wordt een nieuw lukraak nummer tussen 1 en 6 getrokken, enzovoort…
Gebalanceerde randomisatie met blokken van grootte 1 is equivalent aan eenvoudige randomisatie. Dergelijke blokgrootte is dus niet opportuun wanneer men groepen van gelijke grootte wenst te bekomen. Doorgaans is het niettemin zinvol om relatief kleine blokgroottes te beschouwen. Bovenstaande procedure garandeert immers dat, wanneer de studie halfweg een blok eindigt, het verschil in aantal subjecten tussen beide groepen hoogstens de helft van de gekozen blokgrootte bedraagt. Kleine blokken garanderen bijgevolg kleine verschillen in aantallen deelnemers per groep.
Bij een echte randomisatie hoeven de blokken niet allen dezelfde grootte te hebben. Door de lengte van elk blok te variëren (bijvoorbeeld door een lukraak mechanisme) verloopt de reeks toewijzingen van subjecten aan interventie meer lukraak en voorkomt men dat de onderzoeker de blokgrootte ontdekt en als gevolg daarvan de interventiecode van sommige subjecten kan voorspellen. Immers, indien de onderzoeker de blokgrootte kent, dan kan hij net vóór het verstrijken van elk blok voorspellen wat de interventiecode is van het laatste subject. Gebalanceerde randomisatie voor blokken van verschillende grootte is niet veel moeilijker dan voor blokken van gelijke grootte. Voor het vergelijken van 2 interventies zou men bijvoorbeeld telkens eerst lukraak kunnen kiezen uit een blokgrootte van 2, 4 of 6 en vervolgens, zoals voorheen, lukraak een blok van die grootte kiezen.
Beschouw opnieuw het experiment naar het effect van roofvissen op zeebodemhabitats. Stel dat we 12 lukrake gebieden op de zeebodem gemarkeerd hebben en vervolgens wensen te beslissen waar we de experimentele kooien (die effectief vis vasthouden) en de controlekooien zullen plaatsen. Dan zouden we de kooien kunnen randomiseren door op elke plaats een muntje op te gooien en vervolgens een experimentele kooi te plaatsen wanneer men kop gooit en een controlekooi anders. Die procedure is erop gericht te garanderen dat experimentele kooien op vergelijkbare plaatsen opgesteld worden als controlekooien. Om te vermijden dat er, per toeval, meer controlekooien dan experimentele kooien geplaatst worden, kunnen we een gebalanceerde randomisatie uitvoeren met blokken van grootte 2. Hoe men dit kan uitvoeren, ligt echter minder voor de hand. Eén mogelijkheid kan erin bestaan om de verschillende gebieden willekeurig te nummeren en die nummers lukraak dooreen te gooien teneinde een nieuwe nummering te bekomen die gegarandeerd lukraak is. Vervolgens kan men in volgorde van de bekomen nummering blokken van grootte 2 randomiseren om zelfde aantallen experimentele kooien en controlekooien te bekomen.
Zelfs na deze gebalanceerde randomisatie kan het optreden dat, door toeval, alle controlekooien dichter bij de kust belanden dan de experimentele kooien. Dat is niet wenselijk omdat we willen vermijden dat het effect van het verwijderen van roofvis verward wordt met het effect van de afstand tot de kust. Een eenvoudige oplossing lijkt erin te bestaan om de plaatsen op de zeebodem te herrandomiseren tot men een wenselijke opdeling bekomt. Echter, ook die oplossing is niet wenselijk omdat ze steunt om menselijk oordeel en daardoor niet langer een vorm van randomisatie is (d.i. ze biedt niet langer de garantie op een lukrake opstelling).
Om te vermijden dat de controlekooien door toeval relatief gezien dichter bij de kust opgesteld worden, kunnen we de gebalanceerde randomisatie afzonderlijk uitvoeren op de 6 plaatsen die het dichtst bij de kust gelegen zijn en op de 6 overige plaatsen. Op die manier garanderen we dat er zich op de 6 plaatsen die het dichtst bij de kust liggen, 3 controlekooien en 3 experimentele kooien bevinden, en analoog op de 6 plaatsen die het verst van de kust verwijderd zijn. Dergelijke vorm van randomisatie wordt gestratificeerde randomisatie genoemd en het bijhorend design een gerandomiseerd compleet blok design (in het Engels: randomized complete block design). Alternatief kan men de 12 gebieden markeren door eerst 6 plaatsen langs de kust te markeren en vertrekkend vanuit elk van die 6 plaatsen, telkens 2 gebieden af te bakenen op bijvoorbeeld 100 en 500 meter van de kust. Vervolgens kan men alternerend de controlekooi en experimentele kooi op 100 meter van de kust plaatsen. Deze laatste manier van werken is logistiek vaak makkelijker, maar is in mindere mate te verkiezen omdat de toewijzing van de kooien niet gerandomiseerd verloopt en omdat de gekozen gebieden mogelijks niet als een lukrake, representatieve verzameling gebieden op de zeebodem kan gezien worden (het is met name een systematische steekproef). Immers, het zou kunnen dat plaatsen op een afstand van 100 en 500 meter van de kust niet representatief zijn omwille van een ongekende periodiciteit in bepaalde bodemkarakteristieken.
Einde voorbeeld
Gestratificeerde randomisatie (in het Engels: stratified randomisation) is een gebalanceerde randomisatie die afzonderlijk wordt uitgevoerd per groep subjecten met gelijkaardige prognostische factoren11 (bvb. afzonderlijk op plaatsen dicht versus ver van de kust). Ze wordt gebruikt om te voorkomen dat die prognostische factoren door toeval niet gelijk verdeeld zouden zijn over de verschillende interventiegroepen en als gevolg daarvan, net zoals confounders, een storende invloed zouden hebben op de associatie tussen behandeling en respons.
Einde definitie
Randomized complete block designs zijn experimentele designs waarbij men eerst de experimentele subjecten opdeelt in blokken en vervolgens elk niveau van de interventie binnen elk blok toepast en via randomisatie toewijst. Men kan dit realiseren d.m.v. gestratificeerde randomisatie waarbij de stratificatie volgens blokken verloopt. Dergelijke designs worden vaak gebruikt wanneer biologische processen worden bestudeerd, vooral wanneer de uitkomst zó sterk varieert tussen subjecten dat het interventie-effect moeilijk op te pikken is vantussen de vele ruis op de gegevens. Als de gegevens veel minder variabel zijn per blok, laat het randomiseren van de interventie per blok immers toe om het interventie-effect per blok te evalueren met veel minder ruis12. In de biologische wetenschappen stellen blokken vaak experimentele subjecten voor die gelijkaardig zijn in tijd of ruimte, hoewel men ook organismen van dezelfde leeftijd, grootte, … kan beschouwen.
Blok designs worden in de levenswetenschappen ook vaak gebruikt om op een efficiente manier om te gaan met de ruis die wordt veroorzaakt door technische variabiliteit. Bij grotere experimenten is het vaak niet mogelijk om alle experimentele eenheden bijvoorbeeld op hetzelfde moment op te groeien in het labo, zijn meerdere celculturen nodig, zijn meerdere sequeneringsruns nodig voor het bepalen van de genexpressie in alle stalen, … Fluctuaties in de labo-condities , tussen celculturen of van sequeneringsrun tot sequeneringsrun zorgen dan voor extra technische ruis. In een randomized complete block design zal het experiment opgedeeld worden in meerdere blokken (vb. tijdstippen, runs, celculturen) en zal men de behandelingen randomizeren binnen elk blok zodat de interventie-effecten opnieuw met veel minder ruis kunnen worden geschat.
Jacques et al. (2015) onderzochten de impact van oxidatieve stress op het proteome in Arabidopsis thaliana. Hierbij bestudeerden ze het proteoom (alle proteïnen) in catalase knock-out en wild type A. thaliana planten. De planten werden gedurende 5 weken opgegroeid in een groeikamer. Vervolgens werd het proteoom bepaald na een controle behandeling, na 1 uur hoge lichtbehandeling of na 3 uur hoge lichtbehandeling. Het experiment werd op drie verschillende tijdstippen herhaald. Op elk tijdstip werden 6 proteomen geëxtraheerd: 1 proteoom voor elk combinatie van genotype x behandeling. Bijgevolg is dit een randomized complete block design met tijdstip als block.
Einde voorbeeld
Microbe-specifieke molecules (MSM) kunnen door het immuunsysteem van planten worden herkend en een defensieve response induceren die ze resistent maakt tegen bepaalde ziektes. Valdés-López et al. (2014) bestudeerde het effect van MSM op de genexpressie van Soja in een RNA-seq studie13. De planten werden opgegroeid in 12 potten. Elke pot bevatte vijf verschillende planten. Na 3 weken werden alle bladeren geoogst per pot. De bladeren afkomstig van elke pot werden in twee gesneden. De ene helft werd behandeld met een controle de andere helft met MSMs en vervolgens werd het RNA geëxtraheerd. Om voldoende RNA te bekomen werden alle bladhelften afkomstig van dezelfde behandeling en dezelfde pot gebruikt per extract. Het experiment is dus een gerandomiseerd complete block design met pot als block.
Einde voorbeeld
Wanneer een prognostische factor (bvb. afstand tot de kust) ongelijk verdeeld is tussen de verschillende interventiegroepen, dan kan men toch haar eventuele storende invloed beperken door ervoor te corrigeren als voor een confounder. Met andere woorden, het is dan aangewezen om het interventie-effect afzonderlijk te schatten voor subjecten met dezelfde waarde van de prognostische factor (bijvoorbeeld afzonderlijk voor kooien op een afstand van 100 meter van de kust en voor kooien op een afstand van 500 meter van de kust). We zullen dieper ingaan op dergelijke correcties in Sectie 3.4, alsook in het extra deel rond het algemeen lineair regressiemodel voor de studenten Biotechnologie en Biochemie, of in vervolgcursussen Statistiek voor de studenten Biologie.
De volgende secties belichten een aantal verschillende types gerandomiseerd gecontroleerde experimenten.
3.3.3 Parallelle designs
In een parallel design ontvangt 1 groep de testinterventie en de andere groep gelijktijdig de controle interventie. Dit is het eenvoudigste en meest gebruikte design voor gerandomiseerd gecontroleerde studies.
Voorbeeld 3.6 (Kiezelwieren en zware metalen) ````
Medley & Clements (1998) bestudeerden de respons van kiezelwieren op zware metalen zoals zink in rivieren in de Rocky Mountains, Colorado, U.S.A. Ze selecteerden daartoe tussen 4 en 7 plaatsen op 6 rivieren die zwaar vervuild waren met zware metalen. Op elke plaats registreerden ze een aantal fysicochemische variabelen (pH, opgeloste zuurstof, …), de zinkconcentratie en variabelen die de kiezelwieren beschrijven (mate van voorkomen, diversiteit, …). De primaire onderzoeksvraag was of de diversiteit van kiezelwieren gelijk was in 4 groepen met verschillende concentraties zink: \(<20 \mu\)g/l, \(21-50 \mu\)g/l, \(51-200 \mu\)g/l en \(>200 \mu\)g/l.
Einde voorbeeld
3.3.4 Cross-over designs
In een cross-over studie ondergaan alle experimentele subjecten sequentieel alle interventies die in de studie vergeleken worden, maar in een lukrake volgorde. De 2 perioden - 2 behandelingen cross-over studie is er één waarbij subjecten lukraak toegewezen worden aan 1 van 2 groepen. Subjecten in de ene groep krijgen tijdens de eerste periode interventie A toegediend en vervolgens interventie B in de tweede periode. Subjecten in de andere groep krijgen tijdens de eerste periode interventie B toegediend en vervolgens interventie A tijdens de tweede periode.
Feinsinger et al. (1991) onderzochten competitie tussen 3 soorten lage begroeiing in Centraal Ameri- kaanse wouden. Ze voerden een experiment uit om de effecten van 4 interventies (relatieve dichtheid van 1 species, Besleria of Palicourea, en een tweede species Cephaelia was 10:10 (A)14, 90:10 (B), 10:90 (C), 50:50 (D)) na te gaan op responsvariabelen zoals het aantal keren dat een bloem door kolibries wordt bezocht of het aantal zaadjes dat rijpt per bloem. Metingen werden verzameld gedurende 4 tijdsperiodes van telkens 4 tot 6 dagen. Eén van de karakteristieken van hun design was dat elk van 4 bestudeerde planten elke interventie onderging in 1 van de 4 studieperiodes, zij het dat de volgorde waarin de interventies toegepast werden anders waren voor de 4 planten (zie onderstaande tabel).
| Periode | Plant 1 | Plant 2 | Plant 3 | Plant 4 |
|---|---|---|---|---|
| 1 | A | B | C | D |
| 2 | B | C | D | A |
| 3 | C | D | A | B |
| 4 | D | A | B | C |
Einde voorbeeld
Het voordeel van dit design is dat elke plant nu onder elke interventie wordt geëvalueerd en er bijgevolg meer informatie in de gegevens aanwezig is om het interventie-effect in te schatten dan wanneer elke plant slechts onder 1 van de interventies wordt gezien. Immers, dit design laat gedeeltelijk toe om elk subject met zichzelf te vergelijken teneinde iets te leren over het interventie-effect. Men kan aantonen dat dit tot gevolg heeft dat er (doorgaans) veel minder proefsubjecten (d.i. planten) nodig zijn dan in een parallel design om even precies15 het interventie-effect te kunnen schatten. Bovendien laat dit design toe om confounding te vermijden in situaties waar replicatie moeilijk is, zoals volgend voorbeeld illustreert.
Stel dat men het effect van koper wenst te onderzoeken op het zich neerzetten van larven van een species ongewerveld zeedier (bvb. zeepokken). Dan zou men kunnen 2 grote aquaria opzetten, het ene voorzien van een koperoplossing en het andere van een inerte controle oplossing (bvb. zeewater). Stel dat men vervolgens 1000 larven aan elk aquarium toevoegt en na verloop van tijd het aantal larven telt dat zich vasthecht in elk aquarium, dan kan men een geobserveerd verschil tussen beide aantallen niet zomaar toeschrijven aan de koperoplossing omdat ook andere verschillen tussen beide aquaria (bvb. de opstelling ervan) een invloed kunnen hebben op het aantal larven dat zich vastzet. Om dat te vermijden, kan men het experiment in een tweede fase opnieuw uitvoeren, idealiter gebruik makend van dezelfde larven, maar ditmaal de koperoplossing toedienen voor het aquarium dat voorheen met zeewater werd gevuld en vice versa.
Einde voorbeeld
Niettemin zijn er in sommige situaties een aantal problemen met cross-over designs die het inschatten van het interventie-effect compliceren. Een eerste probleem is dat het effect van de interventie in de eerste periode een tijdje kan blijven bestaan in de tweede periode. Men noemt dit een carry-over effect. In dat geval wordt het moeilijk (of zelfs onmogelijk) om de effecten van beide interventies van elkaar te onderscheiden en los te koppelen. Om die reden zijn crossover designs het meest aangewezen voor interventies die slechts een korte termijn effect hebben. Ook wanneer het interventie-effect wijzigt over de tijd is het moeilijk met dit design om correct te beschrijven hoe goed de ene interventie werkt t.o.v. de andere. Men zegt in dat geval dat er een interactie is tussen de interventie en de periode waarin ze toegediend wordt. Omdat dergelijke interacties de analyse van de gegevens bemoeilijken en de resultaten tevens minder precies maken, zijn cross-over designs vooral nuttig voor de studie van responsmetingen die stabiel blijven over een lange tijd heen.
3.3.5 Factoriële designs
Factoriële designs zijn experimentele designs met als doel het effect van meer dan 1 interventie te testen. Deze designs zijn zo opgezet dat alle interventies in combinatie met elkaar voorkomen zodat men interacties tussen interventies kan meten. Ze worden zeer frequent gebruikt in de bio-wetenschappen.
Een interactie tussen 2 interventies drukt uit dat een combinatie van 2 interventies een effect heeft dat groter of kleiner is dan de som van de effecten van de afzonderlijke interventies (op een zekere schaal).
Einde definitie
Maret & Collins (1996) bestudeerden de effecten van (ongewerveld) voedselniveau (d.i. veel of weinig bruine garnalen) en de aan-/afwezigheid van kikkervisjes op de grootte van salamanderlarven. Voor elk van de 4 combinaties van voedselniveau en aan/afwezigheid van kikkervisjes werden 8 aquaria opgezet en na verloop van tijd werd de grootte van de snuit van salamanders in elk aquarium opgemeten. Noteer in het bijzonder de 4 interventies als volgt: A (veel voedsel en kikkervisjes), B (weinig voedsel en kikkervisjes), C (veel voedsel en geen kikkervisjes), D (weinig voedsel en geen kikkervisjes). In de afwezigheid van interacties, drukt een vergelijking van groep A-B met C-D het effect uit van kikkervisjes. Analoog drukt een vergelijking van groep A-C met B-D het effect uit van het voedselniveau. De aanwezigheid van groep D laat toe om interacties te evalueren, d.i. om na te gaan of het effect van het voedselniveau anders is alnaargelang de aanwezigheid van kikkervisjes.
Denk voor dit voorbeeld zelf even na hoe u op basis van gegevens voor groepen A, B, C en D zou nagaan of er een interactie is tussen voedselniveau en de aanwezigheid van kikkervisjes.
Einde voorbeeld
Bovenstaand voorbeeld geeft aan dat, indien men op voorhand weet dat 2 of meerdere interventies niet interageren, factoriële designs toelaten om de effecten van elk van de afzonderlijke interventies te evalueren met kleinere groepen subjecten en meer precisie dan afzonderlijke parallelle designs.
Poulson & Platt (1996) bestudeerden de effecten van lichtinval (nl., bevindt men zich onder het bladerdak, op een plaats waar 1 boom is omgevallen, of op een plaats waar meerdere bomen omgevallen zijn) en hoogte van de zaailingen (1-2 m, 2-4 m of 4-8 m) op het verschil in groei tussen zaailingen van de esdoorn en de beuk. De respons was het verschil in groei tussen gepaarde zaailingen van elke soort. Op elk van de 9 combinaties van lichtinval en hoogte van de zaailingen werden 5 metingen voor de respons verzameld. Hoe zou u het effect van lichtinval op het groeiverschil tussen esdoorn en beuk evalueren? En het effect van de grootte van de zaailingen? Wat betekent het dat er een interactie is tussen de lichtinval en grootte van de zaailingen?
Einde voorbeeld
Voorwaarden om factoriële designs te gebruiken, zijn (a) dat de verschillende interventies kunnen gecombineerd worden (en de combinatie van interventies dus geen hoge risico’s stelt voor de studiesubjecten, d.i. iets waar men vooral bij medische interventies moet waakzaam zijn), en (b) dat men echt geïnteresseerd is in de aanwezigheid van interacties. Factoriële designs bestaan eveneens in complexere vormen waar ze meer dan 2 interventies betrekken. In die gevallen, alsook wanneer elke interventie vele niveaus heeft, kan het aantal combinaties van factoren hoog oplopen en bijgevolg eveneens het aantal subjecten dat in de studie moet opgenomen worden. Om dit te vermijden, kan men overstappen op fractionele factoriële designs waar men niet alle combinaties van interventies probeert uit te testen.
3.3.6 Quasi-experimentele designs
Algemeen noemt men een experiment met test- en controlegroep, maar zonder lukrake allocatie aan 1 van beide interventiegroepen, een quasi-experimenteel design. Het grote nadeel van dit design is dat verschillen tussen beide groepen niet gegarandeerd kunnen toegeschreven worden aan verschillen in behandelingswijze.
Om het effect van een gezondheidscampagne in Wales te evalueren, werd een Engels controlegebied gekozen dat ver van Wales verwijderd was (zodat het niet blootgesteld was aan de campagne) (Tudor-Smith et al., 1998). Metingen werden verzameld in beide gebieden, zowel vóór de campagne als 6 jaar later. Hoewel er verbetering werd opgemerkt over de jaren heen, konden geen verschillende evoluties tussen beide groepen aangetoond worden.
Einde voorbeeld
3.4 Observationele studies
Terwijl in een gecontroleerd experiment de onderzoeker zelf beslist welke subjecten een bepaalde interventie ondergaan, observeert men in een observationele studie verschillende subjecten die (mogelijks om zelfgekozen redenen) verschillende interventies hebben ondergaan en probeert men hier vervolgens het interventie-effect uit af te leiden. Bijvoorbeeld, om na te gaan wat het effect is van de aanwezigheid van de salamandersoort P. glutinosus op de groei van de populatie P. jordani zou men in een observationele studie verschillende studiegebieden vergelijken waar er om natuurlijke redenen al dan niet een populatie P. glutinosus aanwezig is. Dergelijke studies zijn wel gecontroleerd (omdat men studiegebieden met en zonder P. glutinosus vergelijkt), maar niet experimenteel (omdat de onderzoeker niet zelf beslist in welke studiegebieden de salamandersoort P. glutinosus aanwezig is). Inderdaad, in een experimentele studie zou men ingrijpen door in sommige studiegebieden de populatie P. glutinosus te verwijderen en in andere niet.
Het grote nadeel van observationele studies is dat verschillen in uitkomst tussen verschillende interventiegroepen niet gegarandeerd kunnen toegeschreven worden aan de blootstelling of interventie. Dit komt doordat deze groepen vaak in meer verschillen dan alleen hun blootstelling. Problemen van confounding zijn dus inherent aan observationele studies. Stel bijvoorbeeld dat men vaststelt dat de populatie P. jordani sneller groeit in gebieden met dan zonder P. glutinosus. Dan kunnen we besluiten dat er een associatie of verband is tussen de aanwezigheid van P. glutinosus en de populatiegroei van P. jordani. Maar dat op zich bewijst niet dat het toevoegen van de salamandersoort P. glutinosus in gebieden waar ze niet aanwezig is, een gunstig effect zal hebben op de populatiegrootte van P. jordani (d.i. dat het toevoegen van P. glutinosus een causaal effect op P. jordani heeft). Er kunnen immers verborgen confounders zijn: zo zou het kunnen dat men meer kans heeft om P. glutinosus aan te treffen in voedselrijke gebieden, waar de populatie P. jordani ook makkelijker zal toenemen omwille van de aanwezigheid van voedsel (maar niet omwille van de aanwezigheid van P. glutinosus). De rijkdom aan voedsel is in dit geval een confounder omdat (in overeenkomst met de eerdere definitie voor confounders) zowel de aanwezigheid van P. glutinosus als de groei van P. jordani geassocieerd zijn met de rijkdom aan voedsel, maar geen van beiden de rijkdom aan voedsel beïnvloeden.
Omwille van confounders is het belangrijk in observationele studies om bij de subjecten waarvoor metingen verzameld worden, zorgvuldig prognostische factoren voor de bestudeerde uitkomst te meten die mogelijks ook met de blootstelling geassocieerd zijn. Voor die confounders die gemeten zijn, kan men immers corrigeren in de statistische analyse. Bijvoorbeeld, om de vergelijking van gebieden met en zonder P. glutonisus te corrigeren voor de confounder voedselrijkdom, kan men proberen een index te verzamelen voor de voedselrijkdom van elk gebied en vervolgens de analyse afzonderlijk uitvoeren bij gebieden met dezelfde voedselrijkdom. Men zegt dan dat de analyse of het geschatte effect van P. glutonisus op de groei van P. jordani gecontroleerd (in het Engels: adjusted of controlled) werd voor de voedselrijkdom van het studiegebied.
De Universiteit van Californië, Berkeley voerde verschillende jaren terug een observationele studie uit om na te gaan of er geslachtsdiscriminatie was bij de toelatingsexamens. Gedurende de studieperiode namen 8442 jongens en 4321 meisjes deel aan het examen. Ongeveer 44% van de jongens en 35% van de meisjes werd toegelaten tot de universiteit. Ervan uit gaande dat jongens en meisjes even capabel zijn om voor het examen te slagen (er is immers geen bewijs van het tegendeel), krijgen we hier de indruk dat jongens en meisjes anders behandeld worden bij de toelatingsprocedure.
Omdat de toelatingsexamens verschillend waren naargelang de studierichting, werd bovenstaande analyse per studierichting opgesplitst om na te gaan welke faculteiten verantwoordelijk waren voor mogelijke discriminatie. De resultaten voor de 6 grootste richtingen staan in Tabel 3.3 getabuleerd (resultaten voor de andere richtingen waren analoog). In alle studierichtingen ligt het slaagpercentage hoger bij de meisjes dan bij de jongens, behalve in richting E waar de jongens het lichtjes beter doen. Dit lijkt paradoxaal, wetende dat het algemene slaagpercentage voor de jongens dat van de meisjes ruim overstijgt. Hoe kunnen we dit verklaren?
De verklaring is dat de moeilijkheidsgraad van de studierichting (en verwant hiermee de keuze van studierichting) een confounder is voor de associatie tussen geslacht en de slaagkans. Immers, zoals blijkt uit Tabel 3.3 hebben jongens meer de neiging om studierichtingen te kiezen waar de slaagkansen hoog zijn: meer dan 50% van de jongens schreven zich in voor studierichtingen A en B, waar de slaagkansen hoger waren dan 50%; meer dan 90% van de meisjes kandideerde voor de andere studierichtingen die veel zwaardere toelatingsexamens hadden.
De vergelijking van de slaagkansen per studierichting in Tabel 3.3 levert een analyse op die gecontroleerd is voor de keuze van studierichting. Na deze controle blijkt relatief weinig verschil in slaagkansen tussen jongens en meisjes. De statistische les is dat relaties tussen percentages kunnen omkeren naarmate men ze al dan niet in subgroepen bekijkt. Dit noemt men Simpson’s paradox.
| Jongens(aantal) | Jongens(geslaagd %) | Meisjes(aantal) | Meisjes (geslaagd %) | |
|---|---|---|---|---|
| A | 825 | 62 | 108 | 82 |
| B | 560 | 63 | 25 | 68 |
| C | 325 | 37 | 593 | 34 |
| D | 417 | 33 | 375 | 35 |
| E | 191 | 28 | 393 | 24 |
| F | 373 | 6 | 341 | 7 |
Einde voorbeeld
De National Health and Nutrition Examination Survey (NHANES 1) is een studie naar gezondheids- en voedingsgewoontes bij 7188 vrouwen tussen 25 en 74 jaar die opgevolgd werden van 1971 tot 1975 en van 1981 tot 1984 (Schatzkin et al., 1987). De onderzoekers vonden een positieve associatie tussen alcoholconsumptie en borstkanker (d.w.z. een hogere kans op borstkanker bij hogere consumptiegraad). Een grote vraag in deze studie was of deze associatie werkelijk het gevolg was van alcoholconsumptie of het gevolg van een mogelijks groot aantal andere factoren die met alcohol consumptie geassocieerd zijn. Het zou bijvoorbeeld kunnen dat vrouwen die meer alcohol verbruiken ook meer roken en om die reden gemakkelijker borstkanker ontwikkelen. In dat geval kan men door de storende invloed van roken mogelijks waarnemen dat het risico op borstkanker toeneemt met stijgend alcoholverbruik, zelfs wanneer in werkelijkheid het alcoholverbruik geen (causaal) effect heeft op borstkanker. Roken is in dat geval een confounder omdat het hogere risico op borstkanker voor alcoholverbruikers dan niet (alleen) het gevolg is van hun alcoholverbruik, maar (ook of vooral) van hun rookgedrag.
Om de invloed van roken op de associatie tussen borstkanker en alcoholconsumptie te doen verdwijnen, heeft men de statistische analyse uitgevoerd bij vrouwen met hetzelfde rookgedrag. Immers, door de analyse te beperken tot vrouwen met hetzelfde rookgedrag, zijn de groepen vrouwen die wel versus niet alcohol consumeren, beter vergelijkbaar en is er dus niet langer een storende invloed van roken. Men zegt in dat geval dat men in de analyse gecorrigeerd (in het Engels: adjusted) heeft voor het rookgedrag, waarmee men bedoelt dat men het effect van alcohol op borstkanker heeft voorgesteld voor vrouwen met hetzelfde rookgedrag. In deze studie vond men dat er na correctie voor roken een associatie bleef bestaan tussen alcoholverbruik en borstkanker. Men besloot dat alcoholconsumptie een verhoogd risico op borstkanker impliceert.
Einde voorbeeld
Goede analyses van observationele studies controleren voor confounders. In de praktijk is het echter zeer moeilijk om alle mogelijke confounders te kennen voor de associatie tussen een blootstelling en een respons. En zelfs wanneer men ze zou kennen, is het vaak onmogelijk om ze allen te meten. Om die reden zijn de resultaten van observationele studies doorgaans minder betrouwbaar dan de resultaten van gerandomiseerd gecontroleerde experimenten. Niettemin zijn observationele studies krachtig en belangrijk omdat het in vele situaties onmogelijk is om een gerandomiseerd experiment uit te voeren. Zo is het praktisch quasi niet mogelijk om een gerandomiseerde experiment uit te voeren naar het effect van bosbranden op de rijkdom aan ongewervelde dieren in de grond omdat vuur moeilijk te manipuleren valt. Hoewel de onderzoeker in bepaalde studiegebieden brandhaarden kan aanbrengen, bestaat immers steeds het risico dat de brand uit de hand loopt. Om die reden bestudeert men vaak gebieden waar op natuurlijke wijze of door brandstichters brand is ontstaan. Hoewel dergelijke studie typisch te kampen hebben met problemen van confounding, hebben observationele studies, mits correctie voor gemeten confounders, in het verleden heel wat nuttige en correctie informatie gebracht, zoals de boodschap dat roken longkanker veroorzaakt (Doll & Hill, 1964).
Foetussen kunnen in de baarmoeder onderzocht worden via echografie. Verschillende experimenten op dieren hebben aangetoond dat dergelijk onderzoek kan leiden tot laag geboortegewicht. Om na te gaan of dat ook zo is bij mensen werd verschillende jaren terug een observationele studie opgezet in het Johns Hopkins ziekenhuis, Baltimore. Na correctie voor een aantal confounders stelden de onderzoekers vast dat baby’s die via echografie onderzocht werden in de baarmoeder gemiddeld een lager geboortegewicht hadden dan baby’s die niet blootgesteld werden aan echografie. Kunnen we hieruit besluiten dat echografie leidt tot lager geboortegewicht?
Het antwoord is nee. We kunnen dit niet zomaar besluiten omdat de baby’s die blootgesteld waren aan echografie mogelijks niet vergelijkbaar waren met de andere baby’s in de studie. Om een duidelijk antwoord te vinden, werd later een gerandomiseerd gecontroleerde studie uitgevoerd. Deze toonde een matig beschermend effect van echografie aan! De reden dat de observationele studie hier een andere conclusie opleverde, is omdat echografie ten tijde van deze studie vooral werd toegepast bij probleemzwangerschappen. Om die reden waren de baby’s die in de observationele studie waren blootgesteld aan echografie doorgaans a priori minder gezond dan de andere baby’s. Of het al dan niet om een probleemzwangerschap ging, was dus een confounder voor de associatie tussen geboortegewicht en blootstelling aan echografie.
Einde voorbeeld
3.5 Prospectieve studies
In prospectieve studies wenst men een associatie tussen een blootstelling en uitkomst te bepalen door eerst een groep subjecten met de blootstelling en een groep subjecten zonder de blootstelling te identificeren en vervolgens (na zekere tijd) de gewenste uitkomst voor elk subject te observeren. Men kiest bijvoorbeeld 10 studiegebieden met en 10 studiegebieden zonder P. glutinosus en na 5 jaar evalueert men voor elk studiegebied hoe groot de populatie P. jordani is.
Prospectieve studies zijn vaak longitudinaal. Dat betekent dat ze de evolutie van processen over de tijd heen onderzoeken door op verschillende tijdstippen metingen voor respons (en vaak ook blootstelling) te verzamelen. Bijvoorbeeld kan men 10 studiegebieden met en 10 studiegebieden zonder P. glutinosus identificeren en jaarlijks (gedurende 5 jaar) evalueren hoe groot de populatie P. jordani is. Dergelijke prospectieve longitudinale studies laten toe om na te gaan hoe de grootte van de populatie P. jordani evolueert over de tijd in functie van de aanwezigheid van een andere salamandersoort. Ze worden (prospectieve) cohort studies genoemd. Meer algemeen zijn dit longitudinale studies waarbij voor elke subject in de studie op verschillende tijdstippen de uitkomst (en eventueel ook de blootstelling) worden geregistreerd, zonder dat de subjecten noodgedwongen eerst opgedeeld worden in een groep cases met de blootstelling en een groep controles zonder de blootstelling. Bijvoorbeeld kan men lukraak 20 gebieden in de studie opnemen en gedurende 5 jaar, jaarlijks registreren hoe groot de populatie P. jordani en hoe groot de populatie P. glutinosus is. Op basis van al die metingen kan men vervolgens nagaan of er een associatie is tussen de grootte van beide populaties. Merk op dat experimentele studies noodgedwongen prospectief zijn.
Ward & Quinn (1988) verzamelden 37 eicapsules van het schelpdier Lepsiella Vinosa aan de litorale zone en 42 eicapsules aan de mosselzone van een rotsige kust. De onderzoekers wensten na te gaan of er een verschil was in het gemiddeld aantal eitjes per capsule tussen beide zones. Deze studie is prospectief vermits de onderzoekers eerst 2 types studiegebieden (d.i. 2 blootstellingen) identificeren en vervolgens de uitkomst observeren.
Einde voorbeeld
3.6 Retrospectieve studies
In retrospectieve studies wenst men een associatie tussen een blootstelling en een bepaalde aandoening te bepalen door eerst een groep subjecten met de aandoening en een groep subjecten zonder de aandoening te identificeren en vervolgens op te sporen welke blootstelling ze in het verleden ondervonden hebben. Men kiest bijvoorbeeld 100 longkankerpatiënten en 100 mensen zonder longkanker en vergelijkt vervolgens het DNA-profiel tussen beiden. Dergelijke studies worden ook case-controle studies of case-referent studies genoemd omdat de groep subjecten met de aandoening doorgaans cases worden genoemd, en de groep subjecten zonder de aandoening controles. Pas echter op: het is niet omdat men subjecten met (zonder) de aandoening cases (controles) noemt in een bepaalde studie, dat het om een case-controle studie gaat! Zo is ook de Salk vaccin studie geen case-controle studie hoewel gevaccineerde (niet-gevaccineerde) kinderen cases (controles) werden genoemd.
Genetische associatiestudies zijn erop gericht om na te gaan of polymorfismen (d.i. verschillen in DNA sequentie tussen individuen) in bepaalde genen geassocieerd zijn met bepaalde fenotypes, bijvoorbeeld of het polymorfisme in het BRCA1 gen geassocieerd is met borstkanker. Vaak bestudeert men relatief zeldzame aandoeningen, in welk geval case-controle studies zeer efficiënt zijn. Immers, door via het design vast te leggen dat het DNA-profiel moet gemeten worden van 100 borstkankercases en 100 controles kan men met een beperkt aantal metingen toch een voldoende aantal cases evalueren. In prospectieve studies daarentegen zou men met een borstkankerprevalentie van 1% al 10000 mensen moeten evalueren om een 100-tal cases te garanderen.
In dit voorbeeld beschouwen we zo’n case-controle studie die 800 borstkankercases en 572 controles omvatte. Informatie omtrent het BRCA1-polymorfisme werd bekomen via DNA-analyse en staat getabuleerd in Tabel 3.4. We stellen vast dat 89 van de 800 cases het allel Leu/Leu bezitten, of 11.1%, en 56 van de 572 controles, of 9.8%. Dit suggereert dat de aanwezigheid van het allel Leu/Leu prevalenter is bij mensen met borstkanker. In latere hoofdstukken zullen we vaststellen dat dergelijk verschil in prevalentie van blootstelling aan het allel Leu/Leu voldoende klein is om door toeval te kunnen ontstaan wanneer er in werkelijkheid geen associatie is tussen het polymorfisme in BRCA1 en borstkanker. Er is bijgevolg onvoldoende bewijs voorhanden om te kunnen besluiten dat er een associatie is tussen het polymorfisme in BRCA1 en borstkanker.
Merk op dat, hoewel onder de mensen die het allel Leu/Leu bezitten \(89/145=61.4\%\) aan bortskanker lijdt, dit cijfer niet veralgemeenbaar is naar de ganse bevolking. Dit komt doordat het percentage borstkankerpatiënten in deze studie vastgekozen is door het design en dus niet het werkelijke risico op borstkanker weerspiegelt!
| Genotype | Controles | Cases | totaal |
|---|---|---|---|
| Pro/Pro | 266 | 342 | 608 |
| Pro/Leu | 250 | 369 | 619 |
| Leu/Leu | 56 | 89 | 145 |
| Totaal | 572 | 800 | 1372 |
Einde voorbeeld
Er zijn 2 mogelijke variaties van case-controle studies. In niet-gematchte case-controle studies is de controlegroep een goedgekozen steekproef uit de populatie subjecten zonder de aandoening. Het algemeen principe om controles te kiezen is hier (a) om subjecten te kiezen die op basis van hun karakteristieken, maar afgezien van hun uitkomst (bvb. ziektestatus), case zouden kunnen geweest zijn, en (b) om hen onafhankelijk van de blootstelling te kiezen. In gematchte case-controle studies zoekt men voor elke case 1 of meerdere controlesubjecten die vergelijkbaar zijn met de case in termen van belangrijke prognostische variabelen voor de bestudeerde aandoening, zoals leeftijd en geslacht. Bijvoorbeeld kan men voor elke case een controle kiezen van exact dezelfde leeftijd en geslacht. Omdat elke case nu beter vergelijkbaar is met zijn/haar controle verhoogt men aldus de controle voor confounders bij het onderzoeken van het effect van de risicofactor op de uitkomst. Matching kan echter leiden tot een groot verlies aan observaties, met name wanneer heel wat controles verloren gaan doordat ze niet aan de matching criteria voldoen.
Beide types case-controle design vergen elk hun eigen statistische analyse. In deze cursus beperken we ons grotendeels tot niet-gematchte case-controle studies. De analyse van gematchte case-controle studies is complexer omdat deze rekening moet houden met de verwantschap tussen cases en gematchte controles.
Het grote voordeel van case-controle studies is dat ze nuttig aangewend kunnen worden voor de studie van zeldzame aandoeningen. Dit is zo vermits het design toelaat om op voorhand een groep individuen met de aandoening te selecteren en het bijgevolg niet nodig is om te wachten tot een voldoende aantal subjecten de bestudeerde aandoening heeft opgelopen, teneinde over voldoende informatie te beschikken om een accurate vergelijking te maken van het risico in beide blootstellingsgroepen. Een nadeel is dat ze retrospectief zijn en dus beroep doen op historische data of het geheugen van de proefpersonen om informatie te verzamelen over de blootstelling en andere factoren. Dit kan de resultaten mogelijks vertekenen, in welk geval men van recall bias spreekt. Dergelijke vertekening is vooral problematisch wanneer ze niet in even erge mate optreedt voor cases als voor controles. Bijvoorbeeld, omdat cases aan een ziekte lijden, herinneren ze zich vaak beter aan welke risicofactoren ze in het verleden blootgesteld zijn. Als gevolg hiervan kan men bepaalde blootstellingen verkeerdelijk associëren met de bestudeerde ziekte wanneer die blootstellingen in werkelijkheid even prevalent waren voor cases als controles, maar frequenter gerapporteerd werden door cases dan controles. Dergelijke problemen stellen zich minder of niet in genetische associatiestudies waar men via DNA-analyse vroegere `blootstellingen’ opspoort.
Case-controle studies zijn net als cohort studies gevoelig aan het probleem van (ongemeten) confounders. In dat opzicht is een groot nadeel de moeilijke keuze van een goede (d.w.z. vergelijkbare) controlegroep.
3.7 Niet-gecontroleerde studies
In niet-gecontroleerde studies is er geen gelijktijdige controlegroep aanwezig en ondergaan alle subjecten (op elk tijdstip) bijgevolg dezelfde interventie. Vermits er in dergelijke studies geen groep subjecten is die een andere interventie ondergaan, is het moeilijker en vaak zelfs onmogelijk om op basis van deze studies het effect van interventies te evalueren. In deze sectie bespreken we een aantal van deze studies.
3.7.1 Pre-test/Post-test studies
Een pre-test/post-test studie is een studie waarbij een bepaalde karakteristiek gemeten wordt bij een groep subjecten, die vervolgens onderworpen worden aan een zekere interventie en bij wie diezelfde karakteristiek tenslotte opnieuw gemeten wordt. Het behandelingseffect wordt dan vaak gemeten door de metingen na interventie te vergelijken met de metingen vóór interventie. Stel bijvoorbeeld dat men de impact wenst in te schatten van het plaatsen van een waterzuiveringsstation langs een rivier op de biomassa van phytoplankton. Dan zou men op basis van verschillende waterstalen metingen kunnen verrichten zowel vóór als na het plaatsen van het station, en vervolgens beide groepen metingen kunnen vergelijken.
Hoewel dergelijk design zowel metingen met als zonder interventie levert, blijft een groot nadeel de afwezigheid van een controlegroep. Wanneer men een wijziging in uitkomst observeert tussen de tijdstippen van afname van de 2 metingen, kan men immers niet garanderen dat dit het gevolg is van de interventie, vermits ook andere factoren die de uitkomst beïnvloeden, gewijzigd kunnen zijn gedurende de studie. Bijvoorbeeld, hoewel bovenstaande studie nuttige inzichten kan verschaffen in de impact van waterzuiveringsstations, blijft steeds de vraag met dit soort designs of eventuele wijzigingen in de biomassa van phytoplankton toe te schrijven zijn aan het zuiveringsstation of eerder natuurlijke evoluties weerspiegelen ten gevolge van de gewijzigde weersomstandigheden, etc…
3.7.2 Cross-sectionele surveys
Cross-sectionele surveys onderzoeken een groep subjecten op een bepaald punt in de tijd afgezien van hun blootstelling of uitkomst, in tegenstelling tot cohort en case-controle studies. Bijvoorbeeld, stel dat een ecoloog een aantal meren onderzoekt en voor elk meer de grootte opmeet alsook de mate van divergentie in morfologische karakteristieken tussen vissen van een bepaalde species. Dan kunnen de bekomen metingen worden gebruikt om na te gaan of zich meer divergentie voordoet in grote dan in kleine meren. Dit studiedesign wordt cross-sectioneel genoemd omdat men op 1 bepaald tijdstip verschillende subjecten (d.i. meren) onderzoekt, afgezien van blootstelling (d.i. grootte van het meer) of uitkomst (d.i. divergentie).
De resultaten uit cross-sectionele studies kunnen moeilijk interpreteerbaar zijn wanneer ze een tijdscomponent betrekken. Stel bijvoorbeeld dat men in zo’n studie een negatieve associatie vaststelt tussen leeftijd en lichaamslengte. Dan kan dit zijn omdat oudere mensen krimpen, maar ook omdat de jongere generaties doorgaans groter worden dan in het verleden het geval was, of omdat grote mensen sneller sterven!
References
Met “zuiver” wordt hier bedoeld dat de het zuivere interventie-effect uit de gegevens kan gehaald worden zonder dat het antwoord wordt beïnvloed door andere aspecten/variabelen. Dit wordt meer concreet in Hoofdstuk {chap-sample} uitgelegd. Voorlopig volstaat de intuïtieve betekenis van het woord.↩︎
Voorlopig verstaan we onder het feit dat een schatting voor het behandelingseffect `vertekend’ is, dat het foutief werd ingeschat of, m.a.w., dat het geschatte effect niet correct het zuivere effect van de behandeling weerspiegelt. Een meer concrete definitie volgt eveneens in Hoofdstuk {chap-sample}.↩︎
We beklemtonen dat dit in principe zo is, omdat er binnen een beperkt experiment (d.w.z met een relatief klein aantal proefpersonen/proefdieren) uiteraard toevallige verschillen tussen beide groepen kunnen ontstaan; we komen hier later op terug.↩︎
Een prognostische factor is een variabele die sterk geassocieerd is met de bestudeerde uitkomst. Bijvoorbeeld, roken is een prognostische factor voor longkanker omdat het risico op longkanker sterk verschilt tussen rokers en niet-rokers.↩︎
In Hoofdstuk chap-besluit zullen we uitleggen hoe men dit kan realiseren via een gepaarde analyse van de gegevens↩︎
gen-expressie studie waarbij gen-expressie gemeten wordt met next-generation sequencing technologie↩︎
Dus 10% van het gebied wordt uitgemaakt door de ene species, 10% door de andere, en 80% door nog een derde species.↩︎
Wat we concreet bedoelen met het feit dat er minder proefsubjecten nodig zijn om het effect met een gegeven precisie in te schatten. Voorlopig volstaat de intuïtieve betekenis van deze zin.↩︎