Exercise 4.3: Exploring the captopril dataset
Lieven Clement and Jeroen Gilis
statOmics, Ghent University (https://statomics.github.io)
1 The captopril dataset
The captopril dataset holds information on a small experiment with 15 patients that have increased blood pressure values. More specifically, for each patient we will have four values; one value for systolic blood pressure and one for diastolyic, both before and after treating the patient with a drug named captopril.
2 Import the data
## Rows: 15 Columns: 5## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ","
## dbl (5): id, SBPb, DBPb, SBPa, DBPa##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Why is this dataset not tidy?
3 Data visualization
Let’s say we now first want to visualize the data. One possibility to easily visualize the four types of blood pressure values is by adopting the gather function from tidyverse. It will reshape the dataframe, such that we have have a single variable type, which points at one of the four blood pressure types, and bp, which points at the actual value for each type for each patient.
3.1 Barplot
Not all visualization types will be equally informative. Let us first make a barplot of the data. A barplot is a plot that you will commonly find in scientific publication The code for generating such a barplot is provided below:
captopril %>%
gather(type,bp,-id) %>%
Rmisc::summarySE(measurevar="bp",groupvars="type") %>%
ggplot(aes(x=type,y=bp,fill=type)) +
scale_fill_brewer(palette="RdGy") +
theme_bw() +
geom_bar(stat="identity") +
geom_errorbar(aes(ymin=bp-se, ymax=bp+se),width=.2) +
ggtitle("Barplot of different blood pressure measures") +
ylab("blood pressure (mmHg)")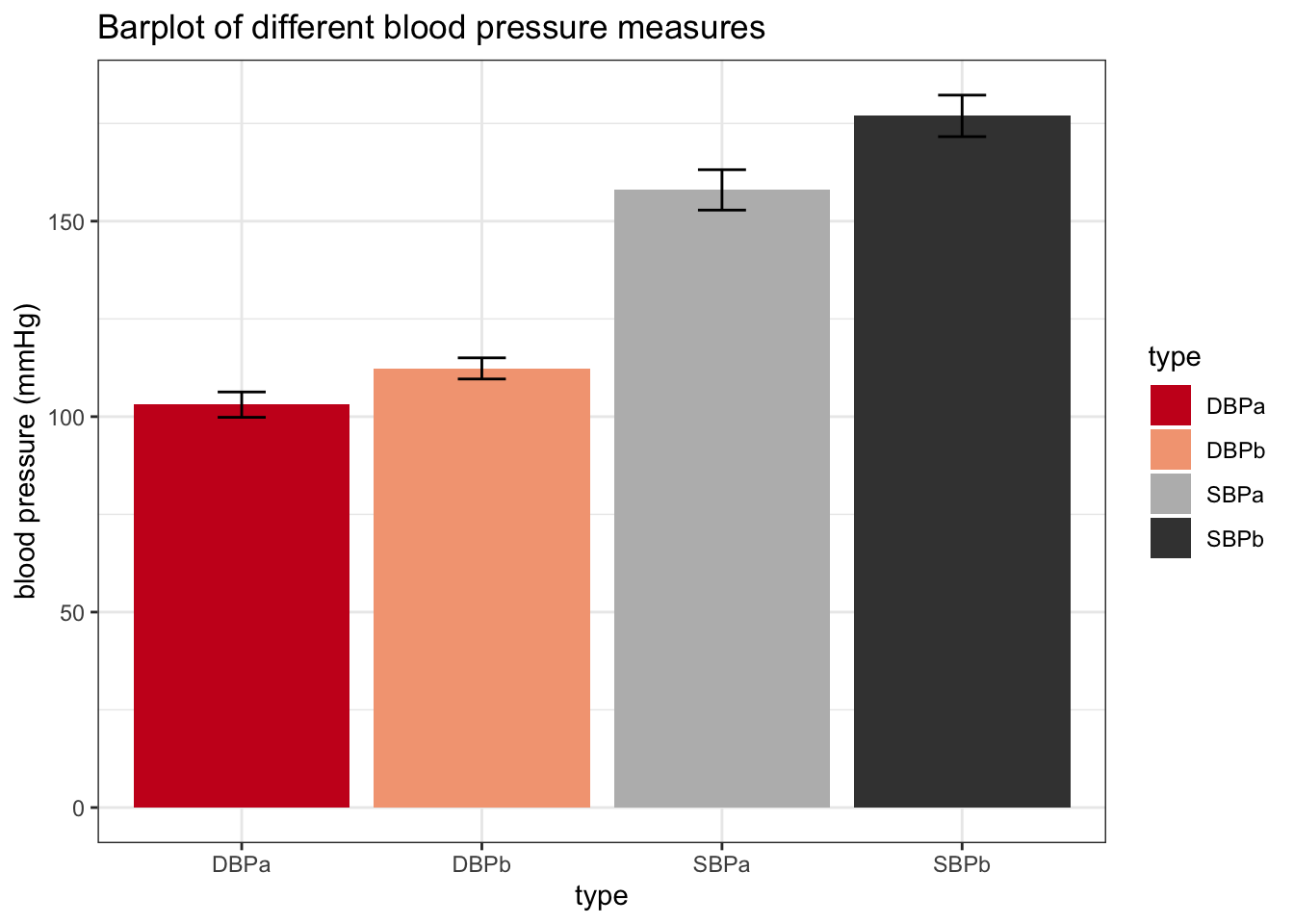
A barplot, however, is not very informative. The height of the bars only provides us with information of the mean blood pressure. However, we don’t see the actual underlying values, so we for instance don’t have any information on the spread of the data. It is usually more informative to represent to underlying values as raw as possible. Note that it is possible to add the raw data on the barplot, but we still would not see any measures of the spread, such as the interquartile range.
Based on this critisism, can you think of a better visualization strategy for the captopril data?
Add your proposed visualization strategy here
3.2 Boxplot
It is usually more informative to represent to underlying values as raw as possible. Boxplots are ideal for this!
Note that it in theory it is possible to add the raw data on the barplot, but we still would not see any measures of the spread, such as the interquartile range.
captopril %>%
gather(type,bp,-id) %>%
ggplot(aes(x=type,y=bp,fill=type)) +
scale_fill_brewer(palette="RdGy") +
theme_bw() +
geom_boxplot(outlier.shape=NA) +
geom_jitter(width = 0.2) +
ggtitle("Boxplot of different blood pressure measures") +
ylab("blood pressure (mmHg)") + stat_summary(fun.y=mean, geom="point", shape=5, size=3, color="black", fill="black")## Warning: `fun.y` is deprecated. Use `fun` instead.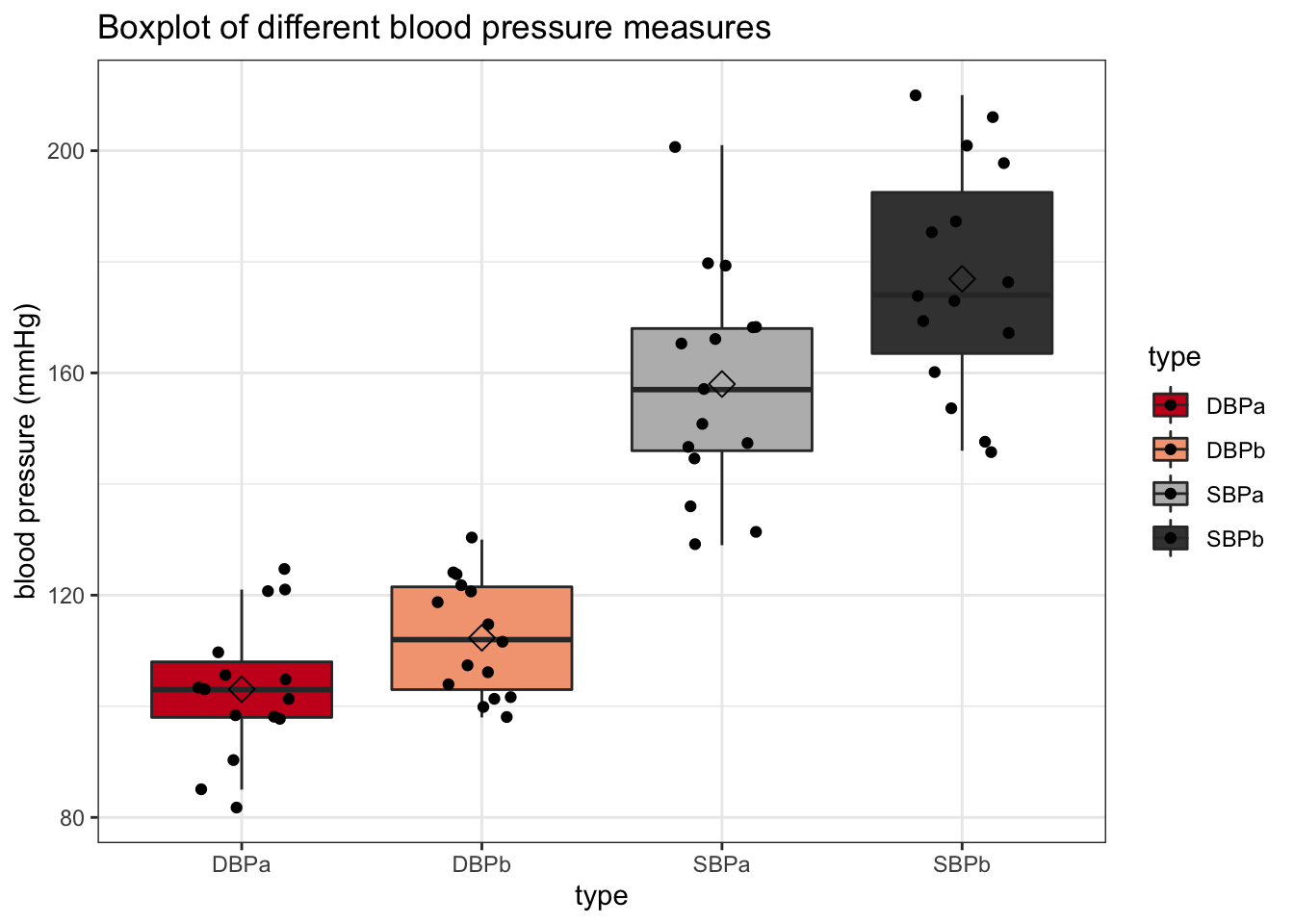
With the boxplot, we get a lot of useful information. We immediately see multiple features of the spread of the data, such as the median, the 25% and 75% quantiles and outliers. Since we only have 15 raw values (patients), we can easily add them to the plot without getting messy.
In terms of interpretation, we can see that the median systolic and diastolic blood pressure values are lower after treatment with captopril than before. If we want to have visual inference on the mean values (cfr. class on t-test), we can add them to the plot stat_summary function.
3.3 Scatterplot
An important feature of this dataset is that it contains paired data; for each patient, we have blood pressure values (systolic and diastolic) before and after treatment with captopril.
We can visualize this as follows;
captopril %>%
gather(type,bp,-id) %>%
filter(type%in%c("SBPa","SBPb")) %>%
ggplot(aes(x=id,y=bp,color=type)) +
geom_point(size=2) +
scale_color_manual(values = c("blue","red")) +
theme_bw()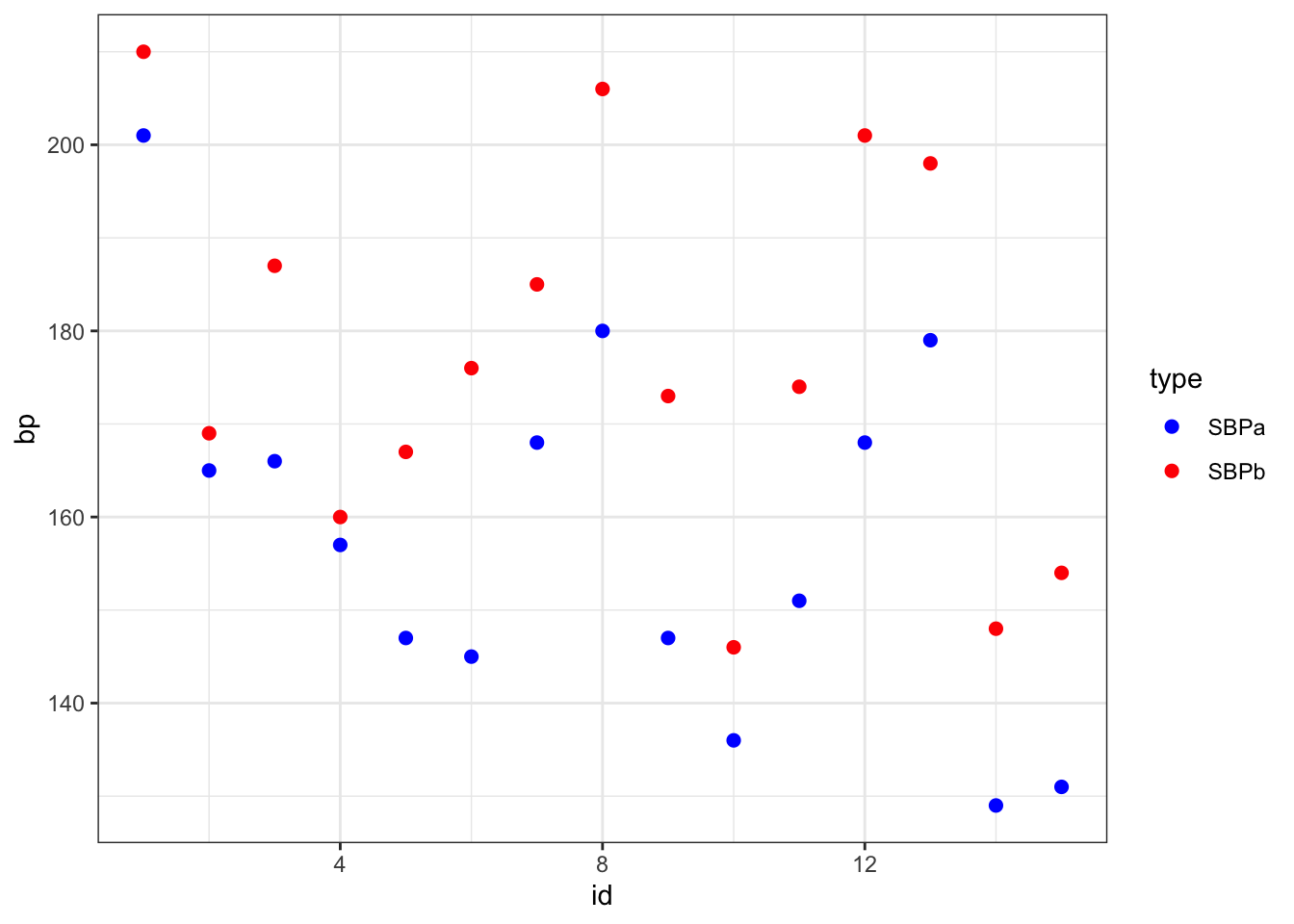
Or, alternatively, by creating a line plot:
captopril %>%
gather(type,bp,-id) %>%
filter(type%in%c("SBPa","SBPb")) %>%
ggplot(aes(x=type,y=bp)) +
geom_line(aes(group=id)) +
theme_bw()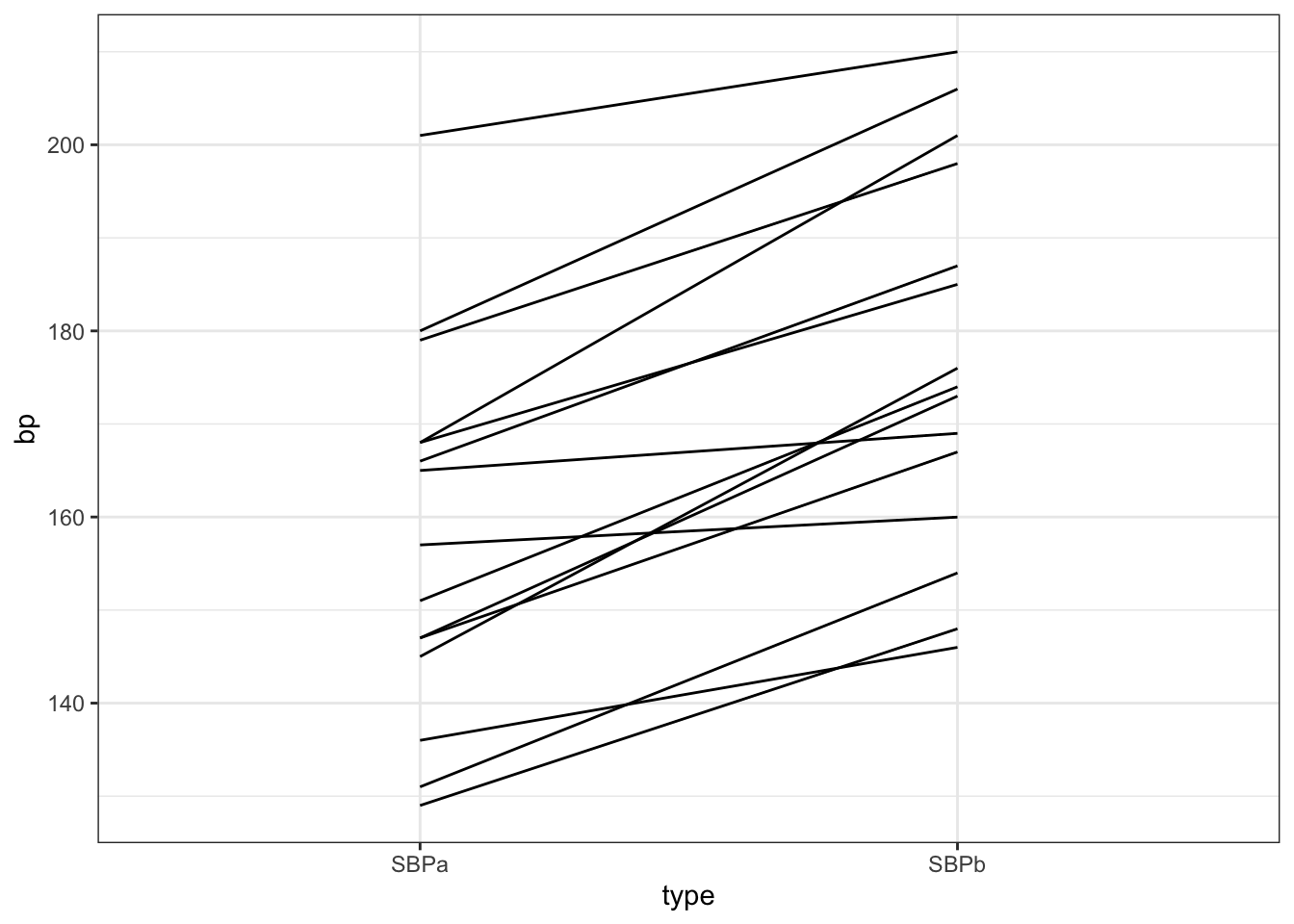
We see that for all patients, the systolic blood pressure is lower after captopril treatment than before.
Note that we could not see this from the boxplot, directly;
captopril %>%
gather(type,bp,-id) %>%
filter(type%in%c("SBPa","SBPb")) %>%
ggplot(aes(x=type,y=bp,fill=type)) +
scale_fill_brewer(palette="RdGy") +
theme_bw() +
geom_boxplot(outlier.shape=NA) +
geom_jitter(width = 0.2) +
ggtitle("Boxplot of blood pressure measures before and after treatment") +
ylab("blood pressure (mmHg)") +
stat_summary(fun=mean, geom="point", shape=5, size=3, color="black", fill="black")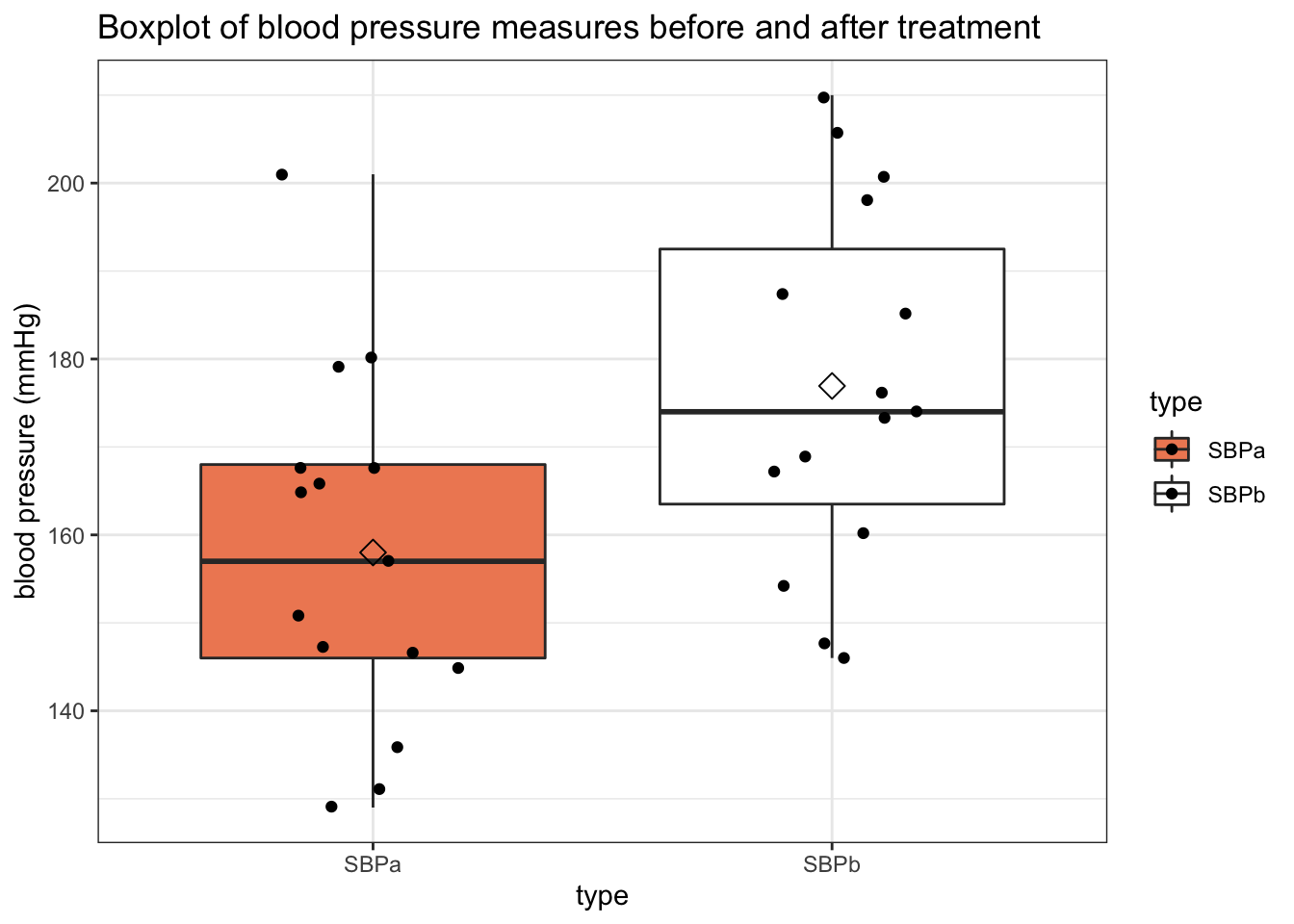
A typical next step is to perform a test to find out whether the mean systolic blood pressure value after captopril treatment is significantly different from the mean systolic blood pressure value before treatment.
Analagously, we may subtract the after measurement from the before measurement, and test if the difference between the two sets of values is significantly different from zero.
captopril %>%
mutate(bp_diff = SBPa-SBPb) %>%
select(bp_diff) %>%
ggplot(aes(x="",y=bp_diff)) +
geom_boxplot(outlier.shape=NA) +
geom_jitter(width = 0.2) +
ggtitle("Boxplot of the difference in blood pressure") +
ylab("blood pressure difference (mmHg)") + stat_summary(fun.y=mean, geom="point", shape=5, size=3, color="black", fill="black") +
theme_bw()+
ylim(-40,10) +
geom_hline(yintercept = 0, color="red") ## adds horizontal line to plot## Warning: `fun.y` is deprecated. Use `fun` instead.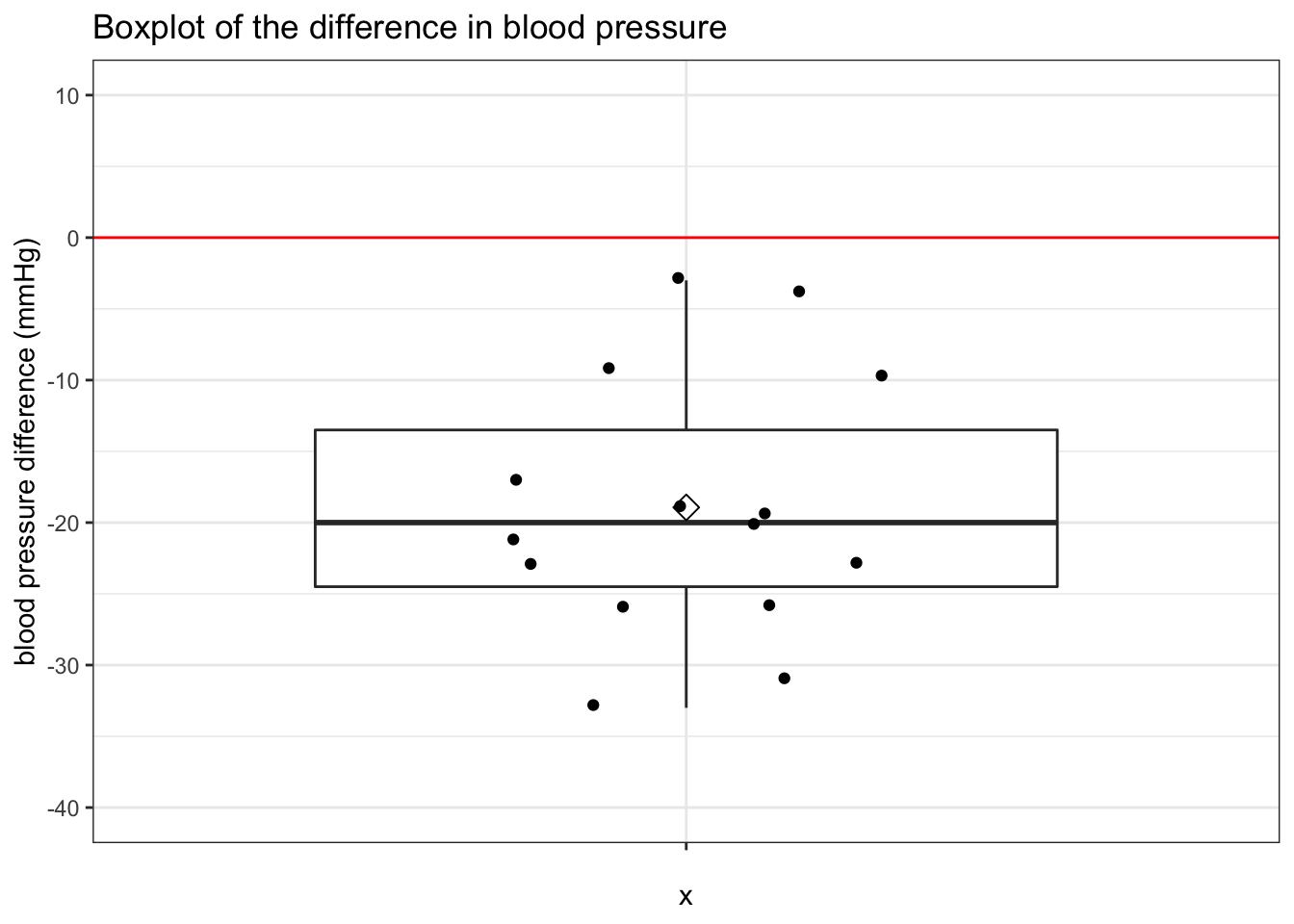
The mean difference is lower than zero. It seems that on average the captopril treatment has lowered the blood pressure by about 20 mmHg. Tomorrow, we will show how we can test if this reduction is significantly different from 0 mmHg.